Web Development BLOG - description
This blog is created by Barry The Analyst, Quality Engineer, Software Development Engineer in Test & owner of this web site, with following references:



Problems solved by language:





Table of Contents
2025
Web deployment
(August)
![]()
![]() Magic squares, X matrix, Snake & Chess problems
(July)
Magic squares, X matrix, Snake & Chess problems
(July)
HTML entity parser, UTF-8 validator & RegEx
(June)
![]()
![]() Map nested in List, sorting & ordered Map
(May)
Map nested in List, sorting & ordered Map
(May)
Two-pointer technique, Dates & circular array
(April)
![]()
![]() String handling & text justifying using Round-Robin
(March)
String handling & text justifying using Round-Robin
(March)
HashSet, nested List and in-place Array modification
(February)
![]()
![]() Basic Array, Dictionary & List handling
(January)
Basic Array, Dictionary & List handling
(January)
2024
Array handling - Remove duplicates, peak index
(December)
![]()
![]() Reversing string words and vowels, reverse integer
(November)
Reversing string words and vowels, reverse integer
(November)
Maximum Depth of Binary Tree
(October)
![]()
![]() Binary Tree Traversal
(September)
Binary Tree Traversal
(September)
Perfect Square, Logarithm, Palindrome, Anagram, Add
(August)
![]()
![]() Binary search, bit count, array compare/2D copy/swap
(July)
Binary search, bit count, array compare/2D copy/swap
(July)
Various Matrix Problems
(June)
![]()
![]() Regular Expressions - Capturing Groups
(May)
Regular Expressions - Capturing Groups
(May)
Regular Expressions - Pattern Recognition
(April)
![]()
![]() Basic combinatorics, GCD and primes
(March)
Basic combinatorics, GCD and primes
(March)
Binary, Hexadecimal and up to 62-base handling
(February)
![]()
![]() Miscellaneous mathematical challenges
(January)
Miscellaneous mathematical challenges
(January)
2023
 Miscellaneous String functions
(December)
Miscellaneous String functions
(December)
![]()
![]() Observer Design Pattern
(November)
Observer Design Pattern
(November)
MVC Application Architecture
(October)
![]()
![]() Pandas JOINs & column suffix, duplicates, NULLs
(September)
Pandas JOINs & column suffix, duplicates, NULLs
(September)
Sorting, filtering & removing duplicates
(August)
![]()
![]() DataFrame grouping & Dense Rank
(July)
DataFrame grouping & Dense Rank
(July)
Categorization & Date handling in pandas
(June)
![]()
![]() Parameterized queries, NULLIF, UNNEST, ARRAY_AGG
(May)
Parameterized queries, NULLIF, UNNEST, ARRAY_AGG
(May)
Running total, PARTITION BY, ROW_NUMBER()
(April)
![]()
![]() Consecutive groups and shifting logic
(March)
Consecutive groups and shifting logic
(March)
Window functions, multi CTEs, DISTINCT ON
(February)
![]()
![]() Scalar Subquery, BETWEEN operator
(January)
Scalar Subquery, BETWEEN operator
(January)

2022
SELECT 1, INDEX, WHERE and HAVING clauses
(December)
![]()
![]() Date functions, COALESCE, FETCH
(November)
Date functions, COALESCE, FETCH
(November)
Count Categories and other challenges
(October)
![]()
![]() SQL Numeric CAST, String handling and CTE
(September)
SQL Numeric CAST, String handling and CTE
(September)
Various SQL Problems
(August)
![]()
![]() SQL Self Join
(July)
SQL Self Join
(July)
SQL INNER and OUTER JOIN
(June)
![]()
![]() SQL Basic Features
(May)
SQL Basic Features
(May)
Web deployment
Saturday, 30.08.2025

 There are 3 deployment environments described:
IIS
on Windows server,
Apache
and
Nging
on Linux server. Full stack app is developed using VSCode, backend in ASP.Net and frontend in React.
There are 3 deployment environments described:
IIS
on Windows server,
Apache
and
Nging
on Linux server. Full stack app is developed using VSCode, backend in ASP.Net and frontend in React.
Repetitive task automation is accomplished with PowerShell scripts and bash scripts, depending on OS. The following tasks are automated:
IIS deployment
 To deploy app to Internet Information Services (IIS) after copying files to target dir full permissions need to be assigned to IIS_IUSRS group. Other prerequisites are to install .Net runtime and WebSocket (using Server Manager) if needed. Backend is to be added in IIS as new App in App pool and frontend as static site, and both to be connected with their physical paths.
To deploy app to Internet Information Services (IIS) after copying files to target dir full permissions need to be assigned to IIS_IUSRS group. Other prerequisites are to install .Net runtime and WebSocket (using Server Manager) if needed. Backend is to be added in IIS as new App in App pool and frontend as static site, and both to be connected with their physical paths.
1. Copy files to server and enable full permissions to IIS_IUSRS group
2. .Net runtime:
3. Backup configuration before WebSocket enabling:
4. Enable WebSocket:
5. Backend setup:
6. Frontend setup:
7. Troubleshooting:
Apache deployment
 To deploy app to Apache web server on Linux after copying files to target dir permissions need to be assigned to www-data group. Since backend is ASP.net Apache will be configured as reverse proxy, which will be defined in
app.conf
file
To deploy app to Apache web server on Linux after copying files to target dir permissions need to be assigned to www-data group. Since backend is ASP.net Apache will be configured as reverse proxy, which will be defined in
app.conf
file
1. Copy files to server and enable permissions to www-data group
In order to configure SSH connection follow these steps
2. Install Apache, ASP.Net Core and modules for Reverse proxy
3. Enable Apache on startup
4. Create previously mentioned config file app.conf in /etc/apache2/sites-available/:
5. Enable site in Apache
6. Once site enabled, check syntax before reloading Apache (Syntax OK expected)
7. Install Node if needed
8. Install Edge browser for Playwright if needed
9. Configure App settings and Start backend
10. Testing
11. Troubleshooting
Nginx deployment
 To deploy app that uses HTTP protocol to Nging web server on Linux, Apache server needs to be stooped and disabled since both would user Port 80. Similar to Apache, config file
nginxAppConfig
file
with proxy settings is to be created and enabled to Nginx.
To deploy app that uses HTTP protocol to Nging web server on Linux, Apache server needs to be stooped and disabled since both would user Port 80. Similar to Apache, config file
nginxAppConfig
file
with proxy settings is to be created and enabled to Nginx.
1. Backup current Apache configuration:
2. Stop and disable Apache (both use port 80)
3. Install Nginx
4. Copy files to server and enable permissions to www-data group
5. Create config file nginxAppConfig in /etc/nginx/sites-available/
6. Create symbolic link to enable configuration:
7. Test the Nginx configuration for syntax errors:
8. Check which user is running (www-data)
Magic squares, X matrix, Snake & Chess problems
Saturday, 05.07.2025
Leetcode Problem 840:
A 3 x 3 magic square is a 3 x 3 grid filled with distinct numbers from 1 to 9 such that each row, column, and both diagonals all have the same sum.
Given a row x col grid of integers, how many 3 x 3 magic square subgrids are there?
Note: while a magic square can only contain numbers from 1 to 9, grid may contain numbers up to 15.
CODE SECTION 24-11-1
public int numMagicSquaresInside(int[][] grid) {
if( grid.length < 3 || grid[0].length < 3 )
return 0;
int magics = 0;
for( int i = 1; i < grid.length-1; i++ ){
for( int j = 1; j < grid[0].length-1; j++ ){
List<Integer> seen = new ArrayList<>(List.of(1, 2, 3, 4, 5, 6, 7, 8, 9));
for( int row = i-1; row < i+2; row++ )
for( int col = j-1; col < j+2; col++ )
seen.remove((Integer)grid[row][col]);
if( seen.size() > 0 ) continue;
if( grid[i-1][j-1]+grid[i-1][j]+grid[i-1][j+1] != 15) continue;
if( grid[i][j-1]+grid[i][j]+grid[i][j+1] != 15) continue;
if( grid[i+1][j-1]+grid[i+1][j]+grid[i+1][j+1] != 15) continue;
if( grid[i-1][j-1]+grid[i][j-1]+grid[i+1][j-1] != 15) continue;
if( grid[i-1][j]+grid[i][j]+grid[i+1][j] != 15) continue;
if( grid[i-1][j+1]+grid[i][j+1]+grid[i+1][j+1] != 15) continue;
if( grid[i-1][j-1]+grid[i][j]+grid[i+1][j+1] != 15) continue;
if( grid[i+1][j-1]+grid[i][j]+grid[i-1][j+1] != 15) continue;
++magics;
}
}
return magics;
} Leetcode Problem 2319: A square matrix is said to be an X-Matrix if both of the following conditions hold: All the elements in the diagonals of the matrix are non-zero. All other elements are 0. Given a 2D integer array grid of size n x n representing a square matrix, return true if grid is an X-Matrix. Otherwise, return false.
CODE SECTION 24-11-2
public boolean checkXMatrix(int[][] grid) {
// Principal diagonal => row = col
// Secondary diagonal => row+col = n-1
int n = grid.length;
for( int row = 0; row < n; row++ )
for( int col = 0; col < n; col++ )
if( row == col || row + col == n-1 ){
if( grid[row][col] == 0 ) return false;
}
else
if( grid[row][col] != 0 ) return false;
return true;
} Leetcode Problem 3248: There is a snake in an n x n matrix grid and can move in four possible directions. Each cell in the grid is identified by the position: grid[i][j] = (i * n) + j. The snake starts at cell 0 and follows a sequence of commands. You are given an integer n representing the size of the grid and an array of strings commands where each command[i] is either "UP", "RIGHT", "DOWN", and "LEFT". It's guaranteed that the snake will remain within the grid boundaries throughout its movement. Return the position of the final cell where the snake ends up after executing commands.
CODE SECTION 24-11-3
public int finalPositionOfSnake(int n, List<String> commands) {
int iCurr = 0, jCurr = 0;
for( String command : commands ){
if( command.equals("UP") ) --iCurr;
else if( command.equals("RIGHT") ) ++jCurr;
else if( command.equals("DOWN") ) ++iCurr;
else if( command.equals("LEFT") ) --jCurr;
}
return iCurr * n + jCurr;
}
Leetcode Problem 999:
 You are given an 8 x 8 matrix representing a chessboard. There is exactly one white rook represented by 'R', some number of white bishops 'B', and some number of black pawns 'p'. Empty squares are represented by '.'.
A rook can move any number of squares horizontally or vertically (up, down, left, right) until it reaches another piece or the edge of the board. A rook is attacking a pawn if it can move to the pawn's square in one move.
Note: A rook cannot move through other pieces, such as bishops or pawns. This means a rook cannot attack a pawn if there is another piece blocking the path.
Return the number of pawns the white rook is attacking.
You are given an 8 x 8 matrix representing a chessboard. There is exactly one white rook represented by 'R', some number of white bishops 'B', and some number of black pawns 'p'. Empty squares are represented by '.'.
A rook can move any number of squares horizontally or vertically (up, down, left, right) until it reaches another piece or the edge of the board. A rook is attacking a pawn if it can move to the pawn's square in one move.
Note: A rook cannot move through other pieces, such as bishops or pawns. This means a rook cannot attack a pawn if there is another piece blocking the path.
Return the number of pawns the white rook is attacking.
CODE SECTION 24-11-4
public int numRookCaptures(char[][] board) {
List<Integer[]> pawns = new ArrayList<>();
List<Integer[]> bishops = new ArrayList<>();
int[] rook = new int[2];
for( int i = 0; i < board.length; i++ )
for( int j = 0; j < board[0].length; j++ )
if( board[i][j] == 'p')
pawns.add(new Integer[]{i,j});
else if( board[i][j] == 'B')
bishops.add(new Integer[]{i,j});
else if( board[i][j] == 'R'){
rook[0] = i;
rook[1] = j;
}
int attacked = 0;
// left
for( int j = rook[1]-1; j>=0; j-- )
if( board[rook[0]][j] == '.' ) continue;
else if( board[rook[0]][j] == 'B' ) break;
else { ++attacked; break; }
// right
for( int j = rook[1]+1; j=0; i-- )
if( board[i][rook[1]] == '.' ) continue;
else if( board[i][rook[1]] == 'B' ) break;
else { ++attacked; break; }
// down
for( int i = rook[0]+1; i < board.length; i++ )
if( board[i][rook[1]] == '.' ) continue;
else if( board[i][rook[1]] == 'B' ) break;
else { ++attacked; break; }
return attacked;
} HTML entity parser, UTF-8 validator & RegEx
Saturday, 07.06.2025
Leetcode Problem 1410:
HTML entity parser is the parser that takes HTML code as input and replaces all the entities of the special characters by the characters itself.
The special characters and their entities for HTML are:
Given the input text string to the HTML parser, you have to implement the entity parser. Return the text after replacing the entities by the special characters.
CODE SECTION 24-10-1
public String entityParser(String text) {
return text
.replace(""", "\"")
.replace("'", "'")
.replace(">", ">")
.replace("<", "<")
.replace("⁄", "/")
.replace("&", "&"); // must be last
}Leetcode Problem 393: Given an integer array data representing the data, return whether it is a valid UTF-8 encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters). A character in UTF-8 can be from 1 to 4 bytes long, subjected to the following rules:
This is how the UTF-8 encoding would work:
| Number of Bytes | UTF-8 Octet Sequence (binary) |
|---|---|
| 1 | 0xxxxxxx |
| 2 | 110xxxxx 10xxxxxx |
| 3 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
x denotes a bit in the binary form of a byte that may be either 0 or 1.
Note: The input is an array of integers. Only the least significant 8 bits of each integer is used to store the data. This means each integer represents only 1 byte of data.
CODE SECTION 24-10-2
public boolean validUtf8(int[] data) {
for( int i = 0; i < data.length; i++ ){
byte lsb = (byte)(data[i] & 0xFF); // Lowest byte (least significant byte)
if( (lsb & 0b10000000 ) == 0 ) continue;
if( (lsb & 0b11100000 ) == 0b11000000 ){
if( i+1 == data.length ) return false;
lsb = (byte)(data[++i] & 0xFF);
if( (lsb & 0b11000000 ) == 0b10000000 ) continue;
else return false;
}
if( (lsb & 0b11110000 ) == 0b11100000 ){
if( i+2 >= data.length ) return false;
lsb = (byte)(data[++i] & 0xFF);
if( (lsb & 0b11000000 ) != 0b10000000 ) return false;
lsb = (byte)(data[++i] & 0xFF);
if( (lsb & 0b11000000 ) == 0b10000000 ) continue;
else return false;
}
if( (lsb & 0b11111000 ) == 0b11110000 ){
if( i+3 >= data.length ) return false;
lsb = (byte)(data[++i] & 0xFF);
if( (lsb & 0b11000000 ) != 0b10000000 ) return false;
lsb = (byte)(data[++i] & 0xFF);
if( (lsb & 0b11000000 ) != 0b10000000 ) return false;
lsb = (byte)(data[++i] & 0xFF);
if( (lsb & 0b11000000 ) == 0b10000000 ) continue;
else return false;
}
else return false;
}
return true;
} Leetcode Problem 1417: You are given an alphanumeric string s. (Alphanumeric string is a string consisting of lowercase English letters and digits). You have to find a permutation of the string where no letter is followed by another letter and no digit is followed by another digit. That is, no two adjacent characters have the same type. Return the reformatted string or return an empty string if it is impossible to reformat the string.
CODE SECTION 24-10-3
public String reformat(String s) {
String digits = s.replaceAll("\\D", ""); // Remove all non-digit characters
String letters = s.replaceAll("\\d", ""); // Remove all digit characters
if( Math.abs(digits.length()-letters.length()) > 1 ) return "";
StringBuilder response = new StringBuilder(digits.length()+letters.length());
int i = 0;
if( digits.length() >= letters.length() )
while( i < digits.length() ){
response.append( String.valueOf(digits.charAt(i)) );
if( i < letters.length() )
response.append( String.valueOf(letters.charAt(i)));
++i;
}
else
while( i < letters.length() ){
response.append( String.valueOf(letters.charAt(i) ));
if( i < digits.length() )
response.append( String.valueOf(digits.charAt(i) ));
++i;
}
return response.toString();
}Leetcode Problem 1805: You are given a string word that consists of digits and lowercase English letters. You will replace every non-digit character with a space. For example, "a123bc34d8ef34" will become " 123 34 8 34". Notice that you are left with some integers that are separated by at least one space: "123", "34", "8", and "34". Return the number of different integers after performing the replacement operations on word. Two integers are considered different if their decimal representations without any leading zeros are different.
CODE SECTION 24-10-4
public int numDifferentIntegers(String word) {
StringBuilder sb = new StringBuilder(word);
for(int i = 0; i < sb.length(); i++ )
if(Character.isLetter(sb.charAt(i)) )
sb.setCharAt(i, ' ');
String[] numbers = sb.toString().split(" ");
HashSet<String> uniques = new HashSet<>();
for( String num : numbers ){
System.out.println(num);
num = num.trim();
if( num.length() > 0 )
uniques.add(num.replaceFirst("^0+(?!$)", ""));
}
return uniques.size();
}Map nested in List, sorting & ordered Map
Saturday, 10.05.2025
Leetcode Problem 260:
Given an integer array nums, in which exactly two elements appear only once and all the other elements appear exactly twice. Find the two elements that appear only once. You can return the answer in any order.
You must write an algorithm that runs in linear runtime complexity and uses only constant extra space.
CODE SECTION 24-09-1
public int[] singleNumber(int[] nums) {
HashMap<Integer, Integer> freqMap = new HashMap<>();
for( int i = 0; i < nums.length; i++ )
freqMap.put( nums[i], freqMap.getOrDefault(nums[i],0)+1 );
List<Integer> singles = new ArrayList<>(2);
for( Map.Entry<Integer, Integer> item : freqMap.entrySet() )
if( item.getValue() == 1 )
singles.add(item.getKey());
return singles.stream().mapToInt(Integer::intValue).toArray();
}
Leetcode Problem 2053:
A distinct string is a string that is present only once in an array.
Given an array of strings arr, and an integer k, return the kth distinct string present in arr. If there are fewer than k distinct strings, return an empty string "".
Note that the strings are considered in the order in which they appear in the array.
Solution: Using LinkedHashMap to preserve element order in the map the way they were added.
CODE SECTION 24-09-2
public String kthDistinct(String[] arr, int k) {
LinkedHashMap<String, Integer> freqMap = new LinkedHashMap<>();
for( String str : arr )
freqMap.put( str, freqMap.getOrDefault(str,0) + 1 );
int i = 1;
for( Map.Entry<String, Integer> item : freqMap.entrySet() )
if( item.getValue() == 1 )
if( i == k ) return item.getKey();
else ++i;
return "";
}Leetcode Problem 692: Given an array of strings words and an integer k, return the k most frequent strings. Return the answer sorted by the frequency from highest to lowest. Sort the words with the same frequency by their lexicographical order.
CODE SECTION 24-09-3
public List<String> topKFrequent(String[] words, int k) {
List<String> TopWords = new ArrayList<>();
HashMap<String, Integer> freqMap = new HashMap<>();
for( String word : words )
freqMap.put( word, freqMap.getOrDefault(word, 0) + 1);
// Sort by value (ascending), then by key (lexicographically)
List<Map.Entry<String, Integer>> freqMapSorted = freqMap.entrySet()
.stream()
.sorted(Comparator
.<Map.Entry<String, Integer>>comparingInt(Map.Entry::getValue)
.reversed()
.thenComparing(Map.Entry<String, Integer>::getKey))
.collect(Collectors.toList());
for( int i = 0; i < k; i++ )
TopWords.add(freqMapSorted.get(i).getKey());
return TopWords;
}Leetcode Problem 1338: You are given an integer array arr. You can choose a set of integers and remove all the occurrences of these integers in the array. Return the minimum size of the set so that at least half of the integers of the array are removed.
CODE SECTION 24-09-4
public int minSetSize(int[] arr) {
HashMap<Integer, Integer> dictFreq = new HashMap<>();
for( int el : arr )
dictFreq.put( el, dictFreq.getOrDefault(el,0)+1 );
int n = arr.length/2;
//Get a sorted HashMap does not preserve insertion order or sorting
//So even if you sort it, the result will lose that order.
List<Map.Entry<Integer, Integer>> sortedDict = dictFreq.entrySet()
.stream()
.sorted(Comparator
.<Map.Entry<Integer, Integer>>comparingInt(Map.Entry::getValue)
.reversed())
.collect(Collectors.toList());
int nSets = 0;
for( Map.Entry<Integer, Integer> item : sortedDict ){
n -= item.getValue(); //sortedDict.entrySet() not needed for List
++nSets;
if( n <= 0 ) break;
}
return nSets;
}Two-pointer technique, Dates & circular array
Saturday, 12.04.2025
Leetcode Problem 244:
Design a data structure that will be initialized with a string array, and then it should answer queries of the shortest distance between two different strings from the array.
Implement the WordDistance class:
Your WordDistance object will be instantiated and called as such:
Solution: Using two-pointer technique on sorted arrays to find the smallest absolute difference between any pair of elements from two arrays, advancing the pointer that points to the smaller index to try to get a closer match.
CODE SECTION 24-08-1
class WordDistance {
String[] _wordsDict = null;
Map<String, List<Integer>> _wordIndices;
public WordDistance(String[] wordsDict) {
_wordsDict = wordsDict;
_wordIndices = new HashMap<>();
for( int i = 0; i < _wordsDict.length; i++ ){
if( !_wordIndices.containsKey(_wordsDict[i]) )
_wordIndices.put(_wordsDict[i], new ArrayList<Integer>());
_wordIndices.get(_wordsDict[i]).add(i);
}
}
public int shortest(String word1, String word2) {
List<Integer> listIdx1 = _wordIndices.get(word1);
List<Integer> listIdx2 = _wordIndices.get(word2);
int iShortest = _wordsDict.length;
int i =0, j=0;
while( i < listIdx1.size() && j < listIdx2.size() ){
iShortest = Math.min(iShortest,
Math.abs( listIdx1.get(i)- listIdx2.get(j)));
if( listIdx1.get(i) < listIdx2.get(j) ) ++i;
else ++j;
}
return iShortest;
}
} Leetcode Problem 3423: Find Maximum Difference Between Adjacent Elements in a Circular Array. Given a circular array nums, find the maximum absolute difference between adjacent elements. Note: In a circular array, the first and last elements are adjacent.
CODE SECTION 24-08-2
public int maxAdjacentDistance(int[] nums) {
int maxDiff = 0;
for( int i = 0; i <= nums.length; i++ ){
int first = i % nums.length;
int second = (i+1) % nums.length;
maxDiff = Math.max(maxDiff, Math.abs(nums[first]-nums[second]));
}
return maxDiff;
}Leetcode Problem 1154: Given a string date representing a Gregorian calendar date formatted as YYYY-MM-DD, return the day number of the year.
CODE SECTION 24-08-3
import java.time.LocalDate;
class Solution {
public int dayOfYear(String date) {
String[] d = date.split("-");
int year = Integer.parseInt(d[0]);
int month = Integer.parseInt(d[1]);
int day = Integer.parseInt(d[2]);
LocalDate dob = LocalDate.of(year, month, day);
return dob.getDayOfYear();
}
}
Leetcode Problem 3280:
You are given a string date representing a Gregorian calendar date in the yyyy-mm-dd format.
date can be written in its binary representation obtained by converting year, month, and day to their binary representations without any leading zeroes and writing them down in year-month-day format.
Return the binary representation of date.
Example:
Input: date = "2080-02-29"
Output: "100000100000-10-11101"
CODE SECTION 24-08-4
public String convertDateToBinary(String date) {
String[] dateParts = date.split("-");
int nPart = Integer.parseInt(dateParts[0]);
StringBuilder sbDateBin = new StringBuilder((int)Math.log(nPart)+20);
for( String part : dateParts ){
nPart = Integer.parseInt(part);
StringBuilder sbPartBin = new StringBuilder((int)Math.log(nPart)+1);
while( nPart > 0 ){
char c = (char)(nPart % 2 + '0');
sbPartBin.insert(0, c);
nPart /= 2;
}
sbPartBin.append("-");
sbDateBin.append(sbPartBin);
}
sbDateBin.deleteCharAt(sbDateBin.length()-1);
return sbDateBin.toString();
}String handling & text justifying using Round-Robin
Saturday, 15.03.2025
Leetcode Problem 68:
Given an array of strings words and a width maxWidth, format the text such that each line has exactly maxWidth characters and is fully (left and right) justified.
You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ' ' when necessary so that each line has exactly maxWidth characters.
Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line does not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.
For the last line of text, it should be left-justified, and no extra space is inserted between words.
Note:
Solution: Applying Round-Robin i.e. cycling through a list repeatedly in order, looping back to the start when the end is reached. In the text justification algorithm this technique is used to distribute extra spaces between words as evenly as possible from left to right, looping back if necessary.
CODE SECTION 24-12-1
public List<String> fullJustify(String[] words, int maxWidth) {
List<String> justified = new ArrayList<>();
int i = 0;
// 1 select n words than fit the line- adding string items to list
// 2 Pad spaces
// 3 use StringBuilder to build Line from string list items
// 4 add line.toString() to justified
// 5 Special handling last line
while( i < words.length ){
int lineLength = words[i].length();
if( lineLength + 1 >= maxWidth ){
StringBuilder line0 = new StringBuilder(words[i]);
while( line0.length() < maxWidth )
line0.append(' ');
justified.add( line0.toString() );
++i;
continue;
}
List<String> line = new ArrayList<>();
line.add(words[i]);
while( ++i < words.length ){
lineLength += words[i].length() + 1;
if( lineLength <= maxWidth ) line.add(' ' + words[i]);
else break;
}
lineLength = 0;
for( String word : line ) lineLength += word.length();
if( i != words.length && line.size() > 1 ) {
int w = 0; // neither last line nor 1-word line
while( lineLength++ < maxWidth ){
line.set(w, line.get(w) + ' ');
w = (w+1) % (line.size() -1); //round-robin space filler
}
}
else // either last line or 1-word line
while( lineLength++ < maxWidth )
line.set(line.size()-1, line.get(line.size()-1) + ' ');
StringBuilder line1 = new StringBuilder();
for( String word : line ) line1.append(word);
justified.add(line1.toString());
}
return justified;
}Leetcode Problem 1592: You are given a string text of words that are placed among some number of spaces. Each word consists of one or more lowercase English letters and are separated by at least one space. It's guaranteed that text contains at least one word. Rearrange the spaces so that there is an equal number of spaces between every pair of adjacent words and that number is maximized. If you cannot redistribute all the spaces equally, place the extra spaces at the end, meaning the returned string should be the same length as text. Return the string after rearranging the spaces.
CODE SECTION 24-12-2
public String reorderSpaces(String text) {
String[] words = text.split(" ");
List<String> cleaned = new ArrayList<>();
int nLetters = 0;
for( String word : words ){
String clean = word.trim();
if( clean.length() > 0 ){
cleaned.add(clean);
nLetters += clean.length();
}
}
StringBuilder sb = new StringBuilder();
if( cleaned.size() == 1 ){
sb.append(cleaned.get(0));
for( int i = 0; i < text.length()-cleaned.get(0).length(); i++)
sb.append(" ");
return sb.toString();
}
int nSpaces = text.length() - nLetters;
int between = nSpaces / (cleaned.size()-1);
int end = nSpaces % (cleaned.size()-1);
for( int i = 0; i < cleaned.size(); i++){
sb.append(cleaned.get(i));
if( i == cleaned.size() -1 )
for( int j = 0; j < end; j++)
sb.append(" ");
else
for( int j = 0; j < between; j++)
sb.append(" ");
}
return sb.toString();
}Leetcode Problem 8: Implement the myAtoi(string s) function, which converts a string to a 32-bit signed integer. The algorithm for myAtoi(string s) is as follows:
Return the integer as the final result.
CODE SECTION 24-12-3
public int myAtoi(String s) {
String str = s.trim();
if (str == null || str.isEmpty()) return 0;
int i = 0;
boolean isNegative = false;
if (i < str.length() && (str.charAt(i) == '-' || str.charAt(i) == '+')){
isNegative = str.charAt(i) == '-';
i++;
}
List<Integer> arDigits = new ArrayList<>();
while (i < str.length() && Character.isDigit(str.charAt(i))) {
if (str.charAt(i) == '0' && arDigits.size() == 0) {
i++;
continue;
}
arDigits.add(str.charAt(i) - '0');
if (arDigits.size() > 10) break;
i++;
}
if (arDigits.size() == 0) return 0;
final int posLimit = Integer.MAX_VALUE; // 2147483647
final int negLimit = Integer.MIN_VALUE; // -2147483648
long absLimit = isNegative ? (long)posLimit + 1 : posLimit;
long firstPart = 0;
// Calculate number manually to avoid parsing issues
for (int digit : arDigits) {
firstPart = firstPart * 10 + digit;
if (firstPart > absLimit)
return isNegative ? negLimit : posLimit;
}
int finalResult = isNegative ? (int)(-firstPart) : (int)firstPart;
return finalResult;
}HashSet, nested List and in-place Array modification
Saturday, 15.02.2025
Leetcode Problem 869: You are given an integer n. We reorder the digits in any order (including the original order) such that the leading digit is not zero. Return true if and only if we can do this so that the resulting number is a power of two.
Solution: 1) Precompute all powers of 2 ≤ 10⁹ (since n ≤ 10⁹).
2) Store their sorted digit strings in a set.
3) Convert n to a string, sort its digits.
4) Return true if the sorted string of n is in the set.
CODE SECTION 25-06-1
public class Solution {
public bool ReorderedPowerOf2(int n) {
// Calculate log base 2 of n
int logValue = (int)(Math.Log(n, 2));
// Check if log2(n) is an integer and 2^(logn) = n
if( Math.Pow(2, logValue) == n ) return true;
HashSet<string> Powers2 = new();
StringBuilder sb = new(9);
for( int i = 4; i < 31; i++ ){ // 2^4=16, 2^30=1,073,741,824
int pow2 = (int)Math.Pow(2,i);
sb.Clear();
while( pow2 > 0 ){
sb.Append((pow2 % 10).ToString());
pow2 /= 10;
}
char[] chars = sb.ToString().ToCharArray();
Array.Sort(chars);
Powers2.Add( new string(chars));
}
sb.Clear();
while( n > 0 ){
sb.Append((n % 10).ToString());
n /= 10;
}
char[] chars1 = sb.ToString().ToCharArray();
Array.Sort(chars1);
return Powers2.Contains( new string(chars1));
}
}
Leetcode Problem 49: Given an array of strings strs, group the anagrams together. You can return the answer in any order.
Example:
Input: strs = ["eat","tea","tan","ate","nat","bat"]
Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
Solution: As you go through each word: 1) Sort the word to get the key.
2) If the key exists in the dictionary, add the original word to the list.
3) If it doesn’t exist, create a new entry with that key and start a new list.
CODE SECTION 25-06-2
public class Solution {
public IList<IList<string>> GroupAnagrams(string[] strs) {
List<IList<string>> groups = new();
Dictionary<string, List<string>> map = new();
for( int i = 0; i < strs.Length; i++ ){
char[] chars = strs[i].ToCharArray();
Array.Sort(chars);
string key = new string(chars);
if( map.ContainsKey(key) ) map[key].Add(strs[i]);
else map[key] = new List<string>{strs[i]};
}
foreach( var item in map ) groups.Add(item.Value);
return groups;
}
}
Leetcode Problem 75: Given an array nums with n objects colored red, white, or blue, sort them in-place so that objects of the same color are adjacent, with the colors in the order red, white, and blue.
We will use the integers 0, 1, and 2 to represent the color red, white, and blue, respectively.
You must solve this problem without using the library's sort function. Example:
Input: nums = [2,0,2,1,1,0]
Output: [0,0,1,1,2,2]
CODE SECTION 25-06-3
public class Solution {
public void SortColors(int[] nums) {
int[] nums02 = (int[])nums.Clone();
int n0 = 0;
int n1 = 0;
int n2 = 0;
foreach( int num in nums02 )
if( num == 0 ) nums[n0++] = 0;
else if( num == 2 ) nums[nums.Length-1-n2++] = 2;
else ++n1;
for( int i = 0; i < n1; i++ )
nums[n0+i] = 1;
}
// Memory-optimized solution:
public void SortColorsMO(int[] nums) {
ushort n0 = 0;
ushort n1 = 0;
for( int i = 0; i < nums.Length; i++ )
if( nums[i] == 0 ) ++n0;
else if( nums[i] == 1 ) ++n1;
for( int i = 0; i < nums.Length; i++ )
if( i < n0 ) nums[i] = 0;
else if( i < n0+n1 ) nums[i] = 1;
else nums[i] = 2;
}
}
Leetcode Problem 80: Given an integer array nums sorted in non-decreasing order, remove some duplicates in-place such that each unique element appears at most twice. The relative order of the elements should be kept the same.
Since it is impossible to change the length of the array in some languages, you must instead have the result be placed in the first part of the array nums. More formally, if there are k elements after removing the duplicates, then the first k elements of nums should hold the final result. It does not matter what you leave beyond the first k elements.
Return k after placing the final result in the first k slots of nums.
Do not allocate extra space for another array. You must do this by modifying the input array in-place with O(1) extra memory.
Solution: Using Two Pointers technique - Splitting array in two zones:
Valid zone — front part of the array where the result is built.
Read zone — rest of the array that is still examined.
Using reading pointer to read the next number, and writing pointer to write the next valid number (i.e., one that is not a third+ duplicate).
CODE SECTION 25-06-4
public class Solution {
public int RemoveDuplicates(int[] nums) {
if( nums.Length < 3 ) return nums.Length;
int iWrite = 2;
for( int iRead = 2; iRead < nums.Length; iRead++ )
if( nums[iRead] != nums[iWrite-2] ){
nums[iWrite] = nums[iRead];
++iWrite;
}
return iWrite;
}
}Basic Array, Dictionary & List handling
Saturday, 18.01.2025
Sorting Dictionary by values using LINQ, then converting dictionary keys to array including taking only first k elements. Example: Leetcode Problem 347 - Given an integer array nums and an integer k, return the k most frequent elements. You may return the answer in any order.
CODE SECTION 25-05-1
public int[] TopKFrequent(int[] nums, int k) {
Dictionary<int,int> dictFreq = new();
foreach( int num in nums )
dictFreq[num] = dictFreq.GetValueOrDefault(num)+1;
// Sort by values descending
var sorted = dictFreq.OrderByDescending(kv => kv.Value);
// Convert to a new dictionary
Dictionary<int, int> sortedDict =
sorted.ToDictionary(kv => kv.Key, kv => kv.Value);
// Take first k elements and convert to array
return sortedDict.Keys.Take(k).ToArray();
}
Leetcode Problem 384: Given an integer array nums, design an algorithm to randomly shuffle the array. All permutations of the array should be equally likely as a result of the shuffling.
Implement the Solution class:
CODE SECTION 25-05-2
public class Solution {
private int[] _nums = null;
Random _random = null;
int[] _shuffled = null;
List<int> _indices = null;
public Solution(int[] nums) {
_nums = nums;
_random = new Random();
_shuffled = new int[_nums.Length];
_indices = new List<int>(_nums.Length);
}
public int[] Reset() {
return _nums;
}
public int[] Shuffle() {
_indices.Clear();
int index = _random.Next(_nums.Length);
while( _indices.Count < _nums.Length ){
while( _indices.Contains(index) )
index = _random.Next(_nums.Length);
_indices.Add(index);
_shuffled[index] = _nums[_indices.Count-1];
}
return _shuffled;
}
}
Leetcode Problem 436: You are given an array of intervals, where intervals[i] = [starti, endi] and each starti is unique.
The right interval for an interval i is an interval j such that startj >= endi and startj is minimized. Note that i may equal j.
Return an array of right interval indices for each interval i. If no right interval exists for interval i, then put -1 at index i.
CODE SECTION 25-05-3
public class Solution {
public int[] FindRightInterval(int[][] intervals) {
int[] rights = new int[intervals.Length];
Dictionary<int, int> starts = new(intervals.Length);
int maxStart = int.MinValue;
for( int i = 0; i < intervals.Length; i++ ){
starts[intervals[i][0]] = i;
maxStart = Math.Max( maxStart, intervals[i][0]);
}
for( int i = 0; i < intervals.Length; i++ ){
int end = intervals[i][1];
if( starts.TryGetValue( end, out int start ) )
rights[i] = start;
else {
int? nextStart = null;
foreach( var item in starts )
if( item.Key > end ){
if( nextStart == null ) nextStart = item.Key;
else nextStart = Math.Min( (int)nextStart, item.Key );
}
rights[i] = nextStart != null ? starts[(int)nextStart] : -1;
}
}
return rights;
}
}
Codewars Problem: Simple remove duplicates. Remove the duplicates from a list of integers, keeping the last ( rightmost ) occurrence of each element.
Example: For input: [3, 4, 4, 3, 6, 3]
Expected output: [4, 6, 3]
CODE SECTION 25-05-4
using System;
using System.Collections.Generic;
public class Solution
{
public static int[] solve(int[] arr){
List<int> response = new List<int>(arr);
HashSet<int> uniques = new();
for( int i = response.Count-1; i >=0; i-- )
if( uniques.Contains(arr[i])) response.RemoveAt(i);
else uniques.Add(arr[i]);
return response.ToArray();
}
}
Codewars Problem:
Given a string with the weights of FFC members in normal order can you give this string ordered by "weights" of these numbers?
The weight of a number will be from now on the sum of its digits.
For example 99 will have "weight" 18, 100 will have "weight" 1 so in the list 100 will come before 99.
Example:
"56 65 74 100 99 68 86 180 90" ordered by numbers weights becomes:
"100 180 90 56 65 74 68 86 99"
When two numbers have the same "weight", let us class them as if they were strings (alphabetical ordering) and not numbers:
180 is before 90 since, having the same "weight" (9), it comes before as a string.
All numbers in the list are positive numbers and the list can be empty.
CODE SECTION 25-05-5
using System;
using System.Collections.Generic;
public class WeightSort {
public static string orderWeight(string strng) {
string[] weights = strng.Split(' ');
List<string> listOrdered = new List<string>(weights.Length);
foreach( string el in weights )
if( el.Trim().Length > 0 )
listOrdered.Add(el.Trim());
Console.WriteLine(strng);
listOrdered.Sort((a, b) => {
int a1 = RecalcWeight(ulong.Parse(a));
int b1 = RecalcWeight(ulong.Parse(b));
if (a1 < b1) return -1;
if (a1 > b1) return 1;
return a.CompareTo(b); // a1 == b1 - sort lexicographically
});
return string.Join(" ", listOrdered );
}
private static int RecalcWeight( ulong n ){
int sum = (int)(n % 10);
n /= 10;
while( n > 0 ){
sum += (int)(n % 10);
n /= 10;
}
return sum;
}
}Array handling - Remove duplicates, peak index
Saturday, 21.12.2024
Leetcode Problem 442:
Given an integer array nums of length n where all the integers of nums are in the range [1, n] and each integer appears at most twice, return an array of all the integers that appears twice.
You must write an algorithm that runs in O(n) time and uses only constant auxiliary space, excluding the space needed to store the output
CODE SECTION 25-03-1
public IList<int> FindDuplicates(int[] nums) {
IList<int> twice = new List<int>();
HashSet<int> freqMap = new();
int len = nums.Length;
for( int i = 0; i < len; i++ )
if( freqMap.Contains(nums[i]) )
twice.Add(nums[i]);
else
freqMap.Add(nums[i]);
return twice;
}Leetcode Problem 2295: You are given a 0-indexed array nums that consists of n distinct positive integers. Apply m operations to this array, where in the ith operation you replace the number operations[i][0] with operations[i][1]. It is guaranteed that in the ith operation: operations[i][0] exists in nums. operations[i][1] does not exist in nums. Return the array obtained after applying all the operations.
CODE SECTION 25-03-2
public int[] ArrayChange(int[] nums, int[][] operations) {
Dictionary<int,int> dict = new();
for( int i = 0; i < nums.Length; i++ )
dict[nums[i]] = i;
foreach( int[] op in operations ){
int idx = dict[op[0]];
nums[idx] = op[1];
dict.Remove(op[0]);
dict[op[1]] =idx;
}
return nums;
}Leetcode Problem 34: Given an array of integers nums sorted in non-decreasing order, find the starting and ending position of a given target value. If target is not found in the array, return [-1, -1]. You must write an algorithm with O(log n) runtime complexity.
CODE SECTION 25-03-3
public int[] SearchRange(int[] nums, int target) {
int iLeft = 0;
int iRight = nums.Length -1;
int[] result = new int[]{-1,-1};
while( iLeft <= iRight ){
if( nums[iLeft] == target )
result[0] = iLeft;
else
++iLeft;
if( nums[iRight] == target )
result[1] = iRight;
else
--iRight;
if(result[0] != -1 && result[1] != -1)
break;
}
return result;
}Leetcode Problem 852: You are given an integer mountain array arr of length n where the values increase to a peak element and then decrease. Return the index of the peak element. Your task is to solve it in O(log(n)) time complexity.
CODE SECTION 25-03-4
public int PeakIndexInMountainArray(int[] arr) {
for( int i = 1; i < arr.Length; i++ )
if( arr[i] < arr[i-1 ])
return i-1;
return arr.Length-1;
}Reversing string words and vowels, reverse integer
Saturday, 16.11.2024
Leetcode Problem 151:
Given an input string s, reverse the order of the words.
A word is defined as a sequence of non-space characters. The words in s will be separated by at least one space.
Return a string of the words in reverse order concatenated by a single space.
Note that s may contain leading or trailing spaces or multiple spaces between two words. The returned string should only have a single space separating the words. Do not include any extra spaces.
CODE SECTION 25-02-1
public string ReverseWords(string s) {
string[] words = s.Split();
StringBuilder reversed = new StringBuilder();
for( int i = words.Length-1; i >=0; i-- ){
string word = words[i].Trim();
if( word.Length > 0 ){
if( reversed.Length > 0 )
reversed.Append(" ");
reversed.Append(word);
}
}
return reversed.ToString();
}Leetcode Problem 557: Given a string s, reverse the order of characters in each word within a sentence while still preserving whitespace and initial word order.
CODE SECTION 25-02-2
public string ReverseWords(string s) {
string[] words = s.Split(' ');
StringBuilder rev = new StringBuilder("");
for( int w = 0; w < words.Length; w++ ){
for( int i = words[w].Length-1; i >=0; i-- )
rev.Append(words[w][i]);
if( w < words.Length -1 )
rev.Append(' ');
}
return rev.ToString();
}Leetcode Problem 345: Given a string s, reverse only all the vowels in the string and return it. The vowels are 'a', 'e', 'i', 'o', and 'u', and they can appear in both lower and upper cases, more than once.
CODE SECTION 25-02-3
public string ReverseVowels(string s) {
StringBuilder str = new StringBuilder(s);
List<int> indices = new();
for( int i = 0; i < s.Length; i++ )
if( "AEIOUaeiou".Contains(s[i]) )
indices.Add(i);
for( int i = 0; i < indices.Count; i++ )
str[indices[i]] = s[indices[indices.Count-1-i]];
return str.ToString();
}Leetcode Problem 7: Given a signed 32-bit integer x, return x with its digits reversed. If reversing x causes the value to go outside the signed 32-bit integer range [-231, 231 - 1], then return 0. Assume the environment does not allow you to store 64-bit integers (signed or unsigned).
CODE SECTION 25-02-4
public int Reverse(int x) {
//Int32.MaxValue 2**31 - 1 = 2,147,483,647
//Int32.MinValue -2**31 = -2,147,483,648
if( x == Int32.MinValue ) return 0;
bool isNegative = x < 0;
x = Math.Abs(x);
int first = x % 10;
x /= 10;
int reversed = 0;
byte digitCount = 0;
while( x > 0 ){
int digit = x % 10;
reversed *=10;
reversed += digit;
++digitCount;
x/=10;
}
//handle overflow
if( digitCount == 9 &&
( first > 2 || ( first == 2 && reversed > 147483647 )))
return 0;
//no overflow
first *= (int)Math.Pow(10, digitCount);
Console.WriteLine($"{digitCount},{first},{reversed}");
reversed += first;
return reversed * (isNegative ? -1 : 1);
}Maximum Depth of Binary Tree
Saturday, 19.10.2024
In order to find the maximum depth of the tree it is used a recursive DFS (depth-first search). The key idea is Each node asks: "What is the depth of my left child and my right child? I’ll return 1 + the bigger of those."
CODE SECTION 22-12-1
let maxDepth = function(root) {
if (!root) return 0;
let left = maxDepth(root.left);
let right = maxDepth(root.right);
return 1 + Math.max(left, right);
};There is an example binary tree to illustrate how recursion function works.
FIGURE 22-12-2
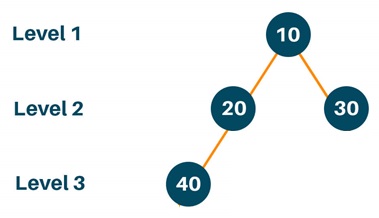
Each node has: val (the value at the node), a left child and a right child. In the example the root node value is 10, left child of root node is 20, right child of the root node is 30, left child of the node 20 is 40, node 20 has no right child, node 30 has neither left nor right child. Base case of the recursion: if the node is null → depth is 0. Recursive case: get the max depth of left and right subtrees. Add 1 (for the current node). The function returns the maximum depth of the current node’s left and right subtrees. Math.max(left, right) chooses the deeper side, and 1 + ... adds 1 for the current node itself (because we count levels starting from this node too).
Recursive call stack
root param = node 10. Checking for null is false 1. level recursive call with left root argument = 20 that is left child of 10 root param = node 20. Checking for null is false 2. level recursive call with left root argument = 40 root param = node 40. Checking for null is false 3. level recursive call with left root argument = null root param = null. Checking for null is true, returns 0 Returned value is 0, saved to left 3. level recursive call with right root argument = null root param = null. Checking for null is true, returns 0 Returned value is 0, saved to right Last line execution, returning 1+max(0,0) - returns 1 Returned value is 1, saved to left 2. level recursive call with right root argument = null root param = null. Checking for null is true, returns 0 Returned value is 0, saved to right Last line execution, returning 1+max(1,0) - returns 2 Returned value is 2, saved to left 1. level recursive call with right root argument = 30 that is right child of 10 root param = node 30. Checking for null is false 2. level recursive call with left root argument = null root param = null. Checking for null is true, returns 0 Returned value is 0, saved to left 2. level recursive call with right root argument = null root param = null. Checking for null is true, returns 0 Returned value is 0, saved to right Last line execution, returning 1+max(0,0) - returns 1 Returned value is 1, saved to right Last line execution, returning 1+max(1,2) - returns 3
Binary Tree Traversal
Saturday, 21.09.2024
Tree traversal (also known as tree search and walking the tree) is a form of graph traversal and refers to the process of visiting (e.g. retrieving, updating, or deleting) each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited.
In depth-first search (DFS), the search tree is deepened as much as possible before going to the next sibling. To traverse binary trees with depth-first search, perform the following operations at each node:
-If the current node is empty then return.
-Execute the following three operations in a certain order:
--Root: Visit the current node
--Left: Recursively traverse the current node's left subtree
--Right: Recursively traverse the current node's right subtree
In-order traversal: order is Left-Root-Right
CODE SECTION 22-11-1
let inorderTraversal = (root) => {
const nodes = [];
getNodes( root, nodes );
return nodes;
};
function getNodes(root, nodes){ //Inorder
if( root === null ) return;
getNodes( root.left, nodes );
nodes.push(root.val);
getNodes( root.right, nodes );
}Pre-order traversal: order is Root-Left-Right
CODE SECTION 22-11-2
let preorderTraversal = (root) => {
const nodes = [];
getNodes( root, nodes );
return nodes;
};
function getNodes(root, nodes){ // Preorder
if( root === null ) return;
nodes.push(root.val);
getNodes( root.left, nodes );
getNodes( root.right, nodes );
}Post-order traversal: order is Left-Right-Root
CODE SECTION 22-11-3
let postorderTraversal = (root) => {
const nodes = [];
getNodes( root, nodes );
return nodes;
};
function getNodes(root, nodes){ // Postorder
if( root === null ) return;
getNodes( root.left, nodes );
getNodes( root.right, nodes );
nodes.push(root.val);
}Level-order or breadth-first search (BFS) traversal, the search tree is broadened as much as possible before going to the next depth. The example given the root of a binary tree returns the level order traversal of its nodes' values. (i.e., from left to right, level by level):
CODE SECTION 22-11-4
let levelOrder = (root) =>{
if( !root ) return [];
const nodes = [];
const queue = [root];
let queueHead = 0; // head pointer to avoid queue unshift()
while( queue.length - queueHead){
const len = queue.length - queueHead;
const level = [];
for( let i =0; i < len; i++ ){
const first = queue[i + queueHead]; // unshift() is expensive
if( first ) {
level.push(first.val);
queue.push(first.left);
queue.push(first.right);
}
}
queueHead += len; // move head pointer forward
if( level.length ) nodes.push(level)
}
return nodes;
};Perfect Square, Logarithm, Palindrome, Anagram, Add
Saturday, 24.08.2024
Difference between squares of 2 numbers is (a+b)(a-b). Since for adjacent numbers a-b=1 the expression equals to 2b+1 which is odd number, the difference of 2 adjacent numbers' squares is always odd. Starting with 1 and adding next odd number we get array of adjacent numbers' squares. The sum of first n odd numbers is n**2 . That can be used to determine perfect square:
CODE SECTION 22-10-1
function isPalindrome(n){
let arDigits = String(n).split('');
for( let i = 0; i < arDigits.length/2; i++ )
if( arDigits[i] != arDigits[arDigits.length-1-i])
return false;
return true;
}
const logBase = (base, arg) => Math.log10(arg) / Math.log10(base);
function isPerfectSquare(num) {
if (num < 1) return false; // Negative numbers and 0 are not perfect squares
let odd = 1;
while (num > 0) {
num -= odd;
odd += 2;
}
return num === 0;
}Checking if 2 passed strings are anagrams and Adding 2 positive numbers passed as strings:
CODE SECTION 22-10-2
let isAnagram = (s, t) => {
if( s.length !== t.length ) return false;
const letters = "abcdefghijklmnopqrstuvwxyz";
const freq = { };
for (let char of letters) freq[char] = 0;
for( let i = 0; i < s.length; i++ ){
freq[s[i]] = freq[s[i]] + 1;
freq[t[i]] = freq[t[i]] - 1;
}
for( let key in freq )
if( freq[key] != 0 )
return false;
return true;
};
let addStrings = (a, b) => {
const result = [];
const length = Math.max( a.length, b.length);
a.length > b.length ? b=b.padStart(length, '0') : a=a.padStart(length,'0');
let iIdx = length-1;
let carry = 0;
while( iIdx >= 0 ){
const res = Number(a[iIdx]) + Number(b[iIdx]) + carry;
result.unshift(res % 10);
res > 9 ? carry = 1 : carry = 0;
--iIdx;
}
carry !== 0 ? result.unshift(carry) : null;
return result.join("");
};Binary search, bit count, array compare/2D copy/swap
Saturday, 27.07.2024
Binary search, also known as half-interval search or logarithmic search, is a search algorithm that finds the position of a target value within a sorted array. Binary search runs in logarithmic time in the worst case, making
O(log n) comparisons, where n is the number of elements in the array.
Binary search can be adapted to compute approximate matches - the rank, predecessor, successor, and nearest neighbor - for the passed element which is not in the array. Binary search implementation:
CODE SECTION 22-09-1
function searchBinary(nums, target){
if( !nums.length ) return -1;
return findElement(nums, 0, nums.length-1, target);
}
function findElement(nums, iStart, iEnd, target){
if( iEnd < iStart )
return -1; // not found, index overlap so no more elements to search
let iMiddle = Math.floor((iEnd-iStart)/2)+iStart;
if( nums[iMiddle] === target )
return iMiddle;
if( nums[iMiddle] > target ) // search left half
return findElement(nums, iStart, iMiddle-1, target );
else // search right half
return findElement(nums, iMiddle+1, iEnd, target );
}FIGURE 22-09-2

Main Array methods are push and pop for handling array end, shift and unshift for handling array beginning. Destructuring assignment is a feature introduced in ECMAScript 2015 (ES6) that allows array or object value assignments to variables, and it can be used for variable swapping as well. Swap array elements in place, compare 1D arrays, copy 2D array, counting bits and counting set bits. Creating frequency map and sort it by values (frequencies).
CODE SECTION 22-09-3
function swapInPlace(arrToSwap, idx1, idx2 ){
[arrToSwap[idx1], arrToSwap[idx2] ] = [arrToSwap[idx2], arrToSwap[idx1] ];
}
function arraysAreEqual(arr1, arr2) {
if (arr1.length !== arr2.length) return false;
return arr1.every((val, index) => val === arr2[index]);
}
function copy2Darray(arr2D){
return arr2D.map(row => [...row]);
}
// Bitwise operators (&, |, ^, ~) only operate on 32-bit signed integers
function countSetBits(n){ // Bitwise approach (Brian Kernighan’s Algorithm)
let count = 0;
while (n > 0) {
n &= (n - 1); // removes the rightmost set bit of n
count++;
}
return count;
}
function bitLength(n) {
if (n === 0) return 1; // Zero requires one bit to represent
let count = 0;
while (n !== 0) {
count++;
n = Math.floor(n / 2);
}
return count;
}
function sortMap(s){
const words = s.split('');
let freq = new Map();
for( let word of words ) freq.set( word, (freq.get(word) || 0) + 1 );
let sorted = new Map( [...freq.entries()].sort((a, b) => b[1] - a[1]) );
}Various Matrix problems
Saturday, 08.06.2024
Given a 0-indexed two-dimensional integer array, Return the largest prime number that lies on at least one of the diagonals of nums. In case, no prime is present on any of the diagonals, return 0.
Principal diagonal => row = col, and secondary => row+col = n-1
CODE SECTION 24-06-1
import { isPrime } from './barry75codebase.js'
let diagonalPrime = function(nums) {
let maxPrime = 0;
const n = nums.length;
for( let row = 0; row < n; row++ ){
if( nums[row][row] > maxPrime && isPrime( nums[row][row]) )
maxPrime = Math.max( maxPrime, nums[row][row] );
if( nums[row][n-row-1] > maxPrime && isPrime( nums[row][n-row-1]) )
maxPrime = Math.max( maxPrime, nums[row][n-row-1] );
}
return maxPrime;
};
Transpose Matrix - recursive solution
CODE SECTION 24-06-2
let transposeMatrix = function(matrix) {
const rows = matrix.length;
const cols = matrix[0].length;
const transposed = [];
for( let col = 0; col < cols; col++ ){
let rowNew = new Array(rows);
for( let row = 0; row < rows; row++ ){
rowNew[row] = matrix[row][col];
if( row === rows - 1 ) transposed.push(rowNew);
}
}
return transposed;
};Matrix Determinant
CODE SECTION 24-06-3
function matrixDeterminant(m) {
if( m.length === 0 )
return 0;
if( m.length === 1 )
return m[0][0];
let detMatrix = 0;
for( let col = 0; col < m[0].length; col++ ){
if( m[0].length === 2 )
return m[0][0]*m[1][1] - m[0][1]*m[1][0];
else {
const subMatrix = getSubMatrix(m, 0, col);
detMatrix += m[0][col]*(((-1)**col) * matrixDeterminant(subMatrix));
}
}
return detMatrix;
}
function getSubMatrix(arrMatrix, rowPivot, colPivot){
const subMatrix = [];
for( let row = 0; row < arrMatrix.length; row++ ) {
if( row === rowPivot )
continue;
const subMatrixRow = [];
for( let col = 0; col < arrMatrix.length; col++ ) {
if( col === colPivot )
continue;
subMatrixRow.push(arrMatrix[row][col]);
}
subMatrix.push(subMatrixRow);
}
return subMatrix;
}Regular Expressions - Capturing Groups
Saturday, 11.05.2024
A capturing group groups a subpattern, allowing you to apply a quantifier to the entire group or use disjunctions within it. It memorizes information about the subpattern match, so that you can refer back to it later with a backreference, or access the information through the match results.
The following RegEx(s)
CODE SECTION 24-04-1
let reverseVowels = function(s) {
let vowels = s.match(/[aeiou]/gi);
return s.replace(/[aeiou]/gi, () => vowels.pop());
};
const code = { a: 1, e: 2, i: 3, o: 4, u: 5 };
const encode = (string) => string.replace(/[aeiou]/g, (matched)=>code[matched]);
const decode = (string) => string.replace(/[1-5]/g, (matched)=>{
for (const [key, value] of Object.entries(code))
if (value == matched) return key; } );
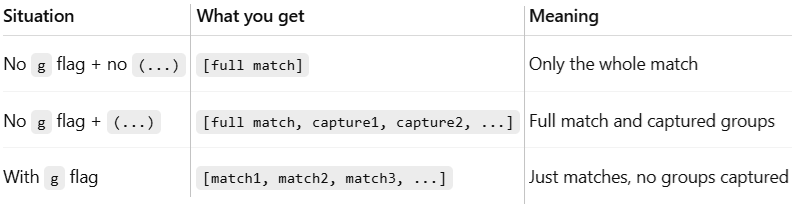
let stringClean = (s) => s.replace(/\d/g, '');In regular expressions, the g/ flag stands for global, and it means: 'Find all matches in the string, not just the first one.' Without /g flag, match and replace method return the first match only - stringClean function would remove the first number only, not all numbers. Method match returns array, replace returns modified string. Array of matched items with /g flag iz 0-based, and without /g flag the first (0th index) item contains the whole string
FIGURE 24-04-2
Passing a function (arrow function) to .replace() method, JavaScript calls it each time a match is found, and return value is different each time. If only vovels.pop() would have been passed, vowels.pop() would have run once, returning one value passed to .replace() as a static replacement string. This would have replaced all vowels with the same letter, the last vowel popped once at the start. Result of regular expression passed to .replace() method is used as an argument for an arrow function passed and that is how replacement is implemented.
The following RegEx(s)
CODE SECTION 24-04-3
function parseIntEx(str) {
const match = str.match(/^\s*([0-9]+)\s*$/);
return match ? parseInt(match[1]) : NaN;
}
const charCodeA = 'A'.charCodeAt(0); // 65
const charCodea = 'a'.charCodeAt(0); // 97
const nextLetter = (str) => {
const s1 = str.replace(/[a-z]/gi, (match) => {
const charCode = match.charCodeAt(0);
if( charCode >= charCodea ) { // lowercase
const code = ( charCode - charCodea +1) % 26;
return String.fromCharCode(code + charCodea);
}
else { // uppercase
const code = ( charCode - charCodeA +1) % 26;
return String.fromCharCode(code + charCodeA);
}
});
return s1;
}The capturing group is defined within parenthesis along with quantifier
If there is no match for the regex [a-z], the .replace() simply returns the original string without calling the callback function even once. So there is no need to check if match before running replace.
The following RegEx will refresh all UUIDs in provided text using replace string method
CODE SECTION 24-04-4
//Run in Browser:
//import { v4 as uuidv4 } from 'https://esm.sh/uuid'; // Use a CDN
//Run in Node: npm install uuid
import { v4 as uuidv4 } from 'uuid';
function refreshUUIDs(strText)
{
const uuidRegex = /\b[a-f0-9]{8}-(?:[a-f0-9]{4}-){3}[a-f0-9]{12}\b/gi;
return strText.replace(uuidRegex, ()=>uuidv4());
} There are following RegEx components:
(?: ) — non-capturing group (just groups the pattern, no saving). In this case there is no need to capture anything because the whole match is being replaces.
\b — word boundary. It matches a position between a word character ([a-zA-Z0-9_]) and a non-word character ([^a-zA-Z0-9_]) or start/end of string.
The following RegEx(s)
CODE SECTION 24-04-5
function validatePassword8(str) {
return /^(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9]).{8,}$/.test(str);
}
function validatePassword6(str) {
return /^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)[A-Za-z0-9]{6,}$/.test(str);
}
function generatePassword(phrase) {
let replaced = phrase.replace(/i/gi, 1).replace(/s/gi, 5).replace(/o/gi, 0);
let words = replaced.match(/\b\w+\b/g).join(' '); // split sentence to words
return words.match(/\b\w/g).join(''); // extract first letter from each word
}There are following RegEx components:
(?=...) — Look ahead to see if something matches. Check if inside the ... there is a match, but don't consume characters.
. → dot = any single character (except line breaks)
* → star = zero or more of the previous thing (which is the dot, so: "zero or more of any character")
In combination .* means: allow any stuff before the uppercase letter / lowercase letter / digit — so we need .* to say "skip over anything until you find one."
.{8,} → matches any character (except line breaks) at least 8 times
Lookaheads check content, . {8,} counts length.
\w+ = one or more "word characters" - letters, digits, underscores.
[\w']+ Including other characters in "word characters" - e.g. apostrophe
\w → one word character (letter, digit, underscore)
Regular Expressions - Pattern Recognition
Saturday, 13.04.2024
Regular expression is a sequence of characters that specifies a match pattern in text. RegEx is used to check if a string contains the specified search pattern. There are different categories of characters, operators, and constructs that can be used to define regular expressions.
The following RegEx return true if given object is a vowel uppercase or lowercase, and false otherwise.
CODE SECTION 24-05-1
String.prototype.vowel = function() {
return /^[aeiou]$/i.test(this);
};There are following RegEx components:
/.../ — start/end of RegEx
^...$ — start/end of string anchors
[...] — character class - “Match exactly one character, and it must be one of these.”
i — case insensitive flag
The following RegEx(s)
CODE SECTION 24-05-2
String.prototype.whitespace=function(){
return /^\s*$/.test(this);
}
let validNumber = (num) => /^[\-\+]?\d*\.\d\d$/.test(num);There are following RegEx components:
\s — space, tab, \n, \t
\d — any digit
? — quantifier 0 or 1
* — quantifier 0 or more
The following RegEx(s)
CODE SECTION 24-05-3
String.prototype.isLetter = function() {
return /^[a-z]$/i.test(this);
}
String.prototype.sixBitNumber = function() {
return /^([\d]|[1-5][\d]|6[0-3])$/.test(this);
}
String.prototype.ipv4Address=function(){
let regEx =
/^(25[0-5]\.|2[0-4]\d\.|1\d\d\.|[1-9]\d\.|\d\.){3}(25[0-5]|2[0-4]\d|1\d\d|[1-9]\d|\d)$/
return regEx.test(this);
}There are following RegEx components:
\d — any digit
| — OR logical operator (has lower precedence than anchors ^ and $)
(...) — grouping logical expressions
{...} — repeating pattern
The following RegEx(s)
CODE SECTION 24-05-4
function validateTime(time) {
// ^ and $ → ensure full string match
// 0?\d → matches 0–9 or 00–09
// 1\d → matches 10–19
// 2[0-3] → matches 20–23
// : — colon separator
// [0-5]\d → matches 00 to 59 (minutes)
return /^(0?\d|1\d|2[0-3]):[0-5]\d$/.test(time);
}
let detectCapitalUse = function(word) {
let regEx = /^([A-Z][a-z]*|[a-z]*|[A-Z]*)$/;
return regEx.test(word);
};
function alphanumeric(string){
return /^[a-z0-9]+$/i.test(string);
}There are following RegEx components:
? — 0 or 1 of the preceding element
* — 0 or more of the preceding element
+ — 1 or more of the preceding element
i — case insensitive flag
Basic combinatorics, GCD and primes
Saturday, 16.03.2024
Greates Common Divisor for 2 numbers is commonly found using Euclidean algorithm. The GCD of two numbers doesn't change if you replace the larger number with its remainder when divided by the smaller. GCD(a, b) = GCD(b, a % b)
CODE SECTION 22-07-1
function findGCD(a, b){
while( b !== 0){
let temp = b;
b = a % b;
a = temp;
}
return a;
}In mathematics, a combination is a selection of items from a set that has distinct members, such that the order of selection does not matter, permutation relates to the act of arranging all the members of a set into some sequence or order. Variation includes all combinations with all permutations.
FIGURE 22-07-2
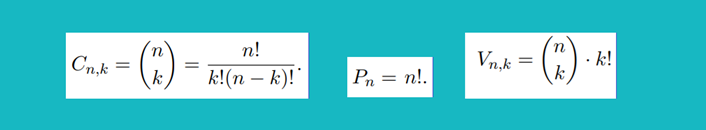
Combinatoric functions for calculating permutations, combinations and variations:
CODE SECTION 22-07-3
const factorial = (n) => n > 1 ? n * factorial(n-1) : 1;
const over = (m,n) => factorial(m) / (factorial(n) * factorial(m-n));
const combinations = (n,r) => over(n,r);
const permutations = (n) => factorial(n);
const variations = (n,r) => combinations(n,r) * permutations(r);Finding first n prime numbers, next prime number above and all prime numbers below:
CODE SECTION 22-07-4
function isPrime(n) {
if ( n < 2 ) return false;
for ( let i = 2; i <= Math.sqrt(n); i++ )
if ( n % i === 0 ) return false;
return true;
}
function getPrimesBelow(n){
const arr = [];
let i = 2;
while (i < n) {
if (isPrime(i)) arr.push(i);
++i;
}
return arr;
}
function getNprimes(n){
const arr = [];
let i = 2;
while (arr.length < n) {
if(isPrime(i)) arr.push(i);
++i;
}
return arr;
}
function getPrimeAbove(n){
while (!isPrime(n)) ++n;
return n;
}Binary, Hexadecimal and up to 62-base handling
Saturday, 17.02.2024
Binary number operations - bit inversion, adding 2 binaries and generating Two-complement. The procedure for obtaining the two's complement representation of a given negative number in binary digits: starting with the absolute binary representation of the number, with the leading bit being a sign bit, inverting (or flipping) all bits, adding 1 to the entire inverted number, ignoring any overflow.
CODE SECTION 22-08-1
function invertBits(s){
return s.split('').map(el=> el=== '0' ? '1' : '0' ).join('');
}
function addBinary(a, b) {
const longer = Math.max(b.length,a.length);
const aBin = a.padStart(longer, '0').split('').map(el=>Number(el));
const bBin = b.padStart(longer, '0').split('').map(el=>Number(el));
const cBin = [];
let carry = 0;
for( let i = aBin.length -1; i >= 0; i-- ){
let sum = aBin[i] + bBin[i] + carry;
carry = Math.floor(sum/2);
cBin.push(String(sum % 2));
}
carry ? cBin.push('1') : null;
return cBin.reverse().join('');
}
function getTwosComplement(s){
let s2 = invertBits(s);
return addBinary(s2,"1");
}Converting positive 64-bit integer to base 2 to base 62 and converting from base 2 to base 62 to positive integer, Converting signed 32-bit integer to hexadecimal number. There are built-in JS functions that partially do the job, but with following limitations:
Finally, reversing bits in 32-bit integer:
CODE SECTION 22-08-2
import { getTwosComplement } from './barry75codebase.js'
function convertToBase2to62(number, base){
if( number <= 0 ) return '0';
const dgs = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
let response = '';
while( number > 0 ){
response = dgs[number%base] + response;
number = Math.floor(number /base);
}
return response;
}
function convertFromBase2to62(str, base){
const dgs = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
let response = 0;
str = str.split('').reverse().join('');
for( let iChar = 0; iChar < str.length; iChar++ ){
const value = dgs.indexOf(str[iChar]);
response += value * (base ** iChar);
}
return response;
}
let toHexadecimal = (num) => { // signed 32-bit integer to hexadecimal
if( num >= 0 ) return convertToBase2to62(num, 16);
let numBin = convertToBase2to62(Math.abs(num), 2);
numBin = getTwosComplement(numBin.padStart(32,'0'));
let n10 = convertFromBase2to62(numBin, 2);
return convertToBase2to62(n10,16);
};
let reverseBits = (n) => { // e.g. From 1101 To 1011 - Input: 13, Output: 11
let arrBinary = convertToBase2to62(n,2).split('');
while( arrBinary.length < 32 ) arrBinary.unshift( '0');
return convertFromBase2to62(arrBinary.reverse().join(''), 2);
};Miscellaneous mathematical challenges
Saturday, 20.01.2024
Checking if number is power of 2 by checking if 1 bit is set. Power of 3 check is done using logarithm on base 3. Number is power of 4 if there is 1 bit set and number of bits is odd (100=4, 10000=16...).
Searching for particular value in 2D-matrix using turning 2D into 1D array by flat() method. Returning number containing last n digits, counting digits in a number and returning number of trailing zeros in n!
CODE SECTION 23-01-1
import { logBase, countSetBits, bitLength, searchBinary }
from './barry75codebase.js'
let isPowerOfTwo = (n) => {
return countSetBits(n) === 1;
};
let isPowerOfThree = (n) => {
if( n < 1 ) return false;
const log3n = logBase(3,n);
return log3n === Math.floor(log3n);
};
let isPowerOfFour = (n) => {
if( n < 1 ) return false;
return countSetBits(n) === 1 && bitLength(n) % 2 === 1;
};
let searchMatrix = (matrix, target) => { // Find target in Matrix
const res= searchBinary(matrix.flat(), target);
return res === -1 ? false : true;
};
const lastNdigits = (num, n) => num % 10 ** n;
const countDigits = (n) => 1 + Math.floor(Math.log10(n));
let trailingZeroes = (n) => { // Return the number of trailing zeroes in n!
let iPower = 1; // There will always be enough 2s
let add = Math.floor(n/5**iPower); // so the number of 5s determines
let zeros = 0; // how many trailing zeroes you get
do{
zeros += add; // zeros = ⌊n/5⌋ + ⌊n/25⌋ + ⌊n/125⌋ + ...
add = Math.floor(n/5**(++iPower));
}while( add > 0 );
return zeros;
};Finding Majority Element that occurs more than n/2 times uses Boyer–Moore majority vote algorithm. If the majority element appears later in the array, the algorithm still works. Early numbers will cancel each other out (some increase count, some decrease it), but once the majority element starts showing up often enough, it will take over the count and never get fully canceled again. The count never goes below 0 in the algorithm. Anytime count would become -1, the code sets a new candidate and resets count = 1.
CODE SECTION 23-01-2
let majorityElement = (nums) => { // Boyer-Moore algorithm >n/2 elements
let candidate = null;;
let count = 0;
for( let i = 0; i < nums.length; i++ ){
if( count === 0 ) candidate = nums[i];
if( nums[i] === candidate ) ++count;
else --count;
}
return candidate;
};
Miscellaneous String functions
Saturday, 23.12.2023
Given two strings ransomNote and magazine, return true if ransomNote can be constructed by using the letters from magazine and false otherwise. Each letter in magazine can only be used once in ransomNote.
Efficiently reverse string in place, works only if string is a character array (string[]), not a JS string, because strings are immutable. Checking if character is English letter A-Z or a-z.
CODE SECTION 23-02-1
import { swapInPlace } from './barry75codebase.js'
let canConstruct = (ransomNote, magazine) => {
const letters = "abcdefghijklmnopqrstuvwxyz";
const freq = { };
for (let char of letters) freq[char] = 0;
for( let char of magazine ) freq[char] += 1;
for( let char of ransomNote ) freq[char] -= 1;
for( let key in freq ) if( freq[key] < 0 ) return false;
return true;
};
let reverseString = (s) => {
for( let i = 0; i < s.length / 2; i++){
swapInPlace(s, i, s.length -1 - i);
}
};
function isLetter(char){
const chUpperCode = char.toUpperCase().charCodeAt(0);
return chUpperCode >= 'A'.charCodeAt(0) && chUpperCode <= 'Z'.charCodeAt(0);
}
let removeElement = (nums, val) => {
let k = 0; // Number of elements not equal to val
for (let i = 0; i < nums.length; i++)
if (nums[i] !== val) {
nums[k] = nums[i]; // Overwrite in-place
k++; // increment k pointer - be filled with next nums[i] !== val
}
return k;
};FIGURE 23-02-2

Given an integer columnNumber, return its corresponding column title as it appears in an Excel sheet. Given a string columnTitle that represents the column title as appears in an Excel sheet, return its corresponding column number.
CODE SECTION 23-02-3
let convertToTitle = (columnNumber) => {
if( columnNumber <= 0 ) return '';
const digits = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
let base = digits.length;
let response = '';
while( number > 0 ){
--number;
response = digits[(number)%base] + response;
number = Math.floor(number /base);
}
return response;
};
let titleToNumber = (columnTitle) => {
const arrCols = columnTitle.split('').reverse();
let column = 0;
const charCodeA = 'A'.charCodeAt(0);
for( let i = 0; i < arrCols.length; i++ ){
const nCol = arrCols[i].charCodeAt(0) - charCodeA + 1;
column += nCol*26**i;
}
return column;
}; Observer Design Pattern
Saturday, 25.11.2023
 The Observer Design Pattern is a behavioral design pattern that defines a one-to-many dependency between objects. When one object (the subject) changes state, all its dependents (observers) are notified and updated automatically. Subjects are the objects that maintain and notify observers about changes in their state, while Observers are the entities that react to those changes.
The Observer Design Pattern is a behavioral design pattern that defines a one-to-many dependency between objects. When one object (the subject) changes state, all its dependents (observers) are notified and updated automatically. Subjects are the objects that maintain and notify observers about changes in their state, while Observers are the entities that react to those changes.
FIGURE 22-06-1
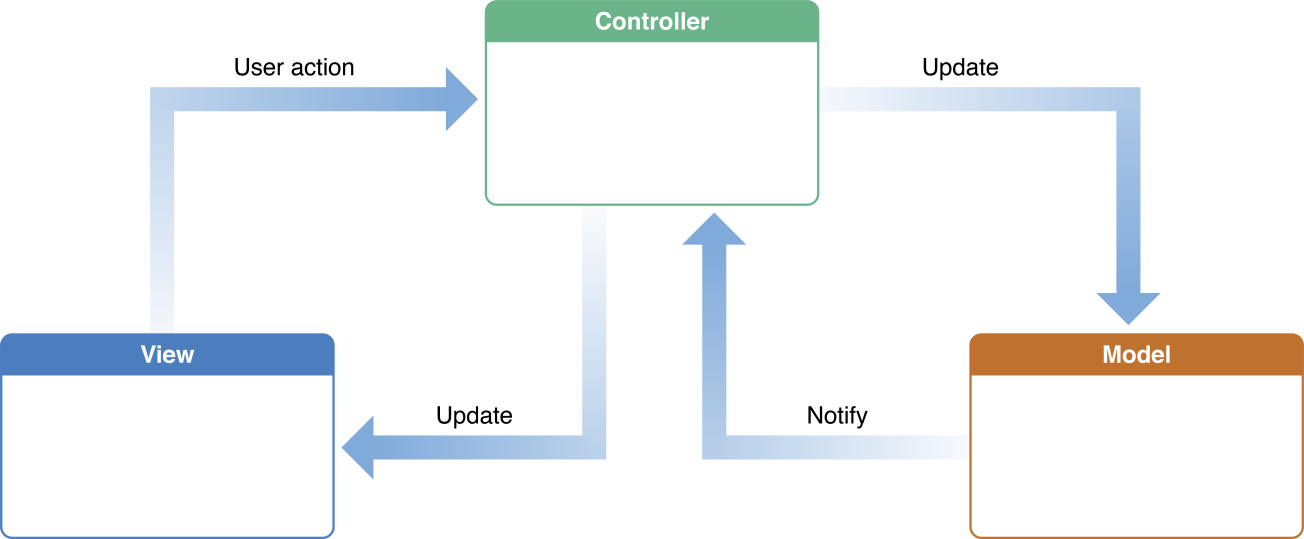
The Observer is a software design pattern in which an object, named the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods.
This pattern contains the following components when implemented in MVC architecture:
CODE SECTION 22-06-2
// model.js
class Model {
constructor() {
this.observers = []; // Array to hold observers (the Controller)
}
// Function to handle changes from Backend and update the model's data
handleChanges(newValue) {
this.data = internalUpdate(newValue);// Handling internal data update
this.notifyObservers(); // Notify all observers (controller)
}
// Function to add an observer (Controller)
addObserver(observer) {
this.observers.push(observer);
}
// Function to notify all observers that data has changed
notifyObservers() {
this.observers.forEach(observer => observer.onModelUpdated(this.data));
}
}
export default Model;CODE SECTION 22-06-3
// view.js
class View {
renderContent(data) {
this.updatePresentation(data) // data parameter provided by Controller
}
}
export default View;CODE SECTION 22-06-4
// controller.js
class Controller {
constructor(model, view) {
// Register the controller as the observer of the model
this.model.addObserver(this); // Controller is the observer now
// Pass the model data to the view for initial rendering
this.view.renderContent(this.model.data);
}
// Function to update the view (called when model data changes)
onModelUpdated(data) {
this.view.renderContent(data); // Pass data as argument to the view
}
}
export default Controller; MVC Application Architecture
Saturday, 28.10.2023
MVC architecture ensures isolation of Model (business logic) and View (presentation logic) from the Controller (application logic). Controller calls functions from Model and from the View, subscribes and listens to updating Model and updates View accordingly in the realtime. Model and View are not aware neither of each other nor of the Controller, they simply sit and wait for their methods to be called by the Controller.
FIGURE 22-05-1
Model-View-Controller is an architectural pattern with primary role to define the architecture of an application by separating concerns—model (data), view (UI), and controller (logic).
Application entry point is app.js where Controller instance is created. Previously created Model and View are passed to Controller constructor.
CODE SECTION 22-05-2
// app.js
import Model from './model.js';
import View from './view.js';
import Controller from './controller.js';
// Create instances of Model and View
const model = new Model();
const view = new View();
// Inject the instances into Controller
const controller = new Controller(model, view);Controller constructor saves passed Model and View instances and calls init() method on each of them
CODE SECTION 22-05-3
// controller.js
import Model from "./model.js";
import View from "./view.js";
class Controller {
constructor(model, view) {
this.model = model;
this.view = view;
// Initialize the app
this.model.init();
this.view.init();
}
}
export default Controller;Pandas JOINs & column suffix, duplicates, NULLs
Saturday, 30.09.2023
Leetcode Problem 1757:
Given a table Products write a solution to find the ids of products that are both low fat AND recyclable. Field product_id is the primary key (column with unique values) for this
low_fats is an ENUM (category) of type ('Y', 'N') where 'Y' means this product is low fat and 'N' means it is not.
recyclable is an ENUM (category) of types ('Y', 'N') where 'Y' means this product is recyclable and 'N' means it is not.
Leetcode Problem 595: Given a table World write a solution to find the name, population, and area of the big countries. Each row of the table gives information about the name of a country (primary key), the continent to which it belongs, its area, the population, and its GDP value. A country is big if it has an area of at least three million (i.e., 3000000 km2), OR it has a population of at least twenty-five million (i.e., 25000000).
CODE SECTION 23-03-1
import pandas as pd
def find_products(prods: pd.DataFrame) -> pd.DataFrame:
df = prods[(prods['low_fats'] == 'Y') & (prods['recyclable'] == 'Y')]
return df[['product_id']]def big_countries(world: pd.DataFrame) -> pd.DataFrame:
df = world[(world['area'] >= 3000000) | (world['population'] >= 25000000)]
return df[['name','population','area']]
Given a table Person - id is the primary key (column with unique values), email column contains an email.
The emails will not contain uppercase letters.
There is
SQL solution
for reporting and deleting duplicates, and pandas solution follows:
Leetcode Problem 182:
Write a solution to report all the duplicate emails. Note that it's guaranteed that the email field is not NULL.
Return the result table in any order.
Solution:
Since merged tables (self-join) both contain id field, fields are renamed to id_x (left table) and id_y (right table),
and these column names are used for excluding self-pairs.
Leetcode Problem 196:
Write a solution to delete all duplicate emails, keeping only one unique email with the smallest id.
Please note that you are supposed to modify Person in place.
After running your script, the answer shown is the Person table. The driver will first compile and run your piece of code and then show the Person table. The final order of the Person table does not matter.
CODE SECTION 23-03-2
import pandas as pd
def duplicate_emails(person: pd.DataFrame) -> pd.DataFrame:
df=pd.merge(person, person, how='inner', on='email')
df = df[df['id_x'] != df['id_y']][['email']]
df.columns=['Email']
return df.drop_duplicates()def delete_duplicate_emails(person: pd.DataFrame) -> None:
person.sort_values(by='id', inplace=True) # sort by id ascending
person.drop_duplicates(subset=['email'], inplace=True, keep='first')Leetcode Problem 183: Write a solution to find all customers who never order anything.
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
The Customers table consists of
id as the primary key (column with unique values),
and name of a customer.
| Column Name | Type |
|---|---|
| id | int |
| customerId | id |
In the Orders table id is the primary key (column with unique values) and
customerId is a foreign key (reference columns) of the ID from the Customers table.
Each row of this table indicates the ID of an order and the ID of the customer who ordered it.
Solution: Instead of default suffixes _x and _y, suffixes can be custom-defined.
Checking for NULL value is implemented using isna() function.
Since joining columns have different names, instead of on it needs to be used left_on and right_on
There is SQL solution for comparison.
CODE SECTION 23-03-3
import pandas as pd
def find_customers(customers: pd.DataFrame, orders: pd.DataFrame)->pd.DataFrame:
df=pd.merge(customers, orders, how='left', left_on='id',
right_on='customerId', suffixes=('_cust', '_order') )
df= df[df['id_order'].isna()][['name']]
df.columns=['Customers']
return dfSELECT Customers.Name AS Customers
FROM Customers
LEFT JOIN Orders
ON Customers.id = Orders.customerId
WHERE Orders.id IS nullSorting, filtering & removing duplicates
Saturday, 05.08.2023
Leetcode Problem 2990:
Given a table Loans
containing loan_id, user_id, and loan_type, with loan_id as column of unique values for this table.
Write a solution to find all distinct user_id's that have at least one Refinance loan type and at least one Mortgage loan type.
Return the result table ordered by user_id in ascending order.
CODE SECTION 25-01-1
def loan_types(loans: pd.DataFrame) -> pd.DataFrame:
dfR = loans[loans['loan_type']=='Refinance']
dfM = loans[loans['loan_type']=='Mortgage']
df = loans[(loans['user_id'].isin(dfR['user_id']))
& (loans['user_id'].isin(dfM['user_id']))]
df = df[['user_id']].drop_duplicates()
return df.sort_values(by='user_id') Leetcode Problem 3051: In the Table Candidates (candidate_id, skill) is the primary key (columns with unique values). Each row includes candidate_id and skill. Write a query to find the candidates best suited for a Data Scientist position. The candidate must be proficient in Python, Tableau, and PostgreSQL. Return the result table ordered by candidate_id in ascending order.
CODE SECTION 25-01-2
import pandas as pd
def find_candidates(candidates: pd.DataFrame) -> pd.DataFrame:
df = candidates[candidates['skill'].isin({'Python', 'Tableau', 'PostgreSQL'})]
df = df.groupby('candidate_id', as_index=False).agg(count1=('skill', 'count'))
return df[df['count1']==3][['candidate_id']]Leetcode Problem 2987: In the Table Listings listing_id is column of unique values. This table contains listing_id, city, and price. Write a solution to find cities where the average home prices exceed the national average home price. Return the result table sorted by city in ascending order.
CODE SECTION 25-01-3
import pandas as pd
def find_expensive_cities(listings: pd.DataFrame) -> pd.DataFrame:
avgNational = listings['price'].mean()
df = listings.groupby('city')['price'].mean().reset_index()
return df[df['price']>avgNational][['city']]Leetcode Problem 1571: In the table Warehouse (name, product_id) is the primary key (combination of columns with unique values). Each row of this table contains the information of the products in each warehouse. In the table Products product_id is the primary key (column with unique values). Each row of this table contains product name and information about the product dimensions (Width, Lenght, and Height) in feets of each product. Write a solution to report the number of cubic feet of volume the inventory occupies in each warehouse. Return the result table in any order.
CODE SECTION 25-01-4
import pandas as pd
def warehouse_manager(whs: pd.DataFrame, products: pd.DataFrame) ->pd.DataFrame:
df = whs.merge(products, on='product_id', how='inner')
df['volume'] = df['Width']*df['Length']*df['Height']*df['units']
# Option 1: as_index=False (a bit faster):
df = df.groupby('name', as_index=False)['volume'].sum()
# Option 2: as_index=True(default):
#df = df.groupby('name')['volume'].sum().reset_index()
df = df.rename(columns= {'name':'warehouse_name'})
return df[['warehouse_name','volume']]
DataFrame grouping & Dense Rank
Saturday, 08.07.2023
Leetcode Problem 2026:
Given a table Problems
problem_id is the primary key column.
Each row of this table indicates the number of likes and dislikes for a LeetCode problem.
Find the IDs of the low-quality problems. A LeetCode problem is low-quality if the like percentage of the problem (number of likes divided by the total number of votes) is strictly less than 60%.
Return the result table ordered by problem_id in ascending order.
CODE SECTION 25-07-1
import pandas as pd
def low_quality_problems(problems: pd.DataFrame) -> pd.DataFrame:
df = problems
df = df[df['likes']/(df['likes']+df['dislikes']) < 0.6]
return df.sort_values(by='problem_id')[['problem_id']] Leetcode Problem 1303: In the Table Employee employee_id is the primary key (column with unique values) for this table. Each row of this table contains the ID of each employee and their respective team. Write a solution to find the team size of each of the employees. Return the result table in any order.
CODE SECTION 25-07-2
import pandas as pd
def team_size(employee: pd.DataFrame) -> pd.DataFrame:
df = employee.groupby('team_id', as_index=False)
.agg(team_size=('team_id','count'))
df = employee.merge(df,how='inner',on='team_id')
return df[['employee_id','team_size']]
"""
-Default is as_index=True. They work the same because pandas is able to merge
a DataFrame using either a column or an index, as long as the key (team_id)
exists in both — even if one is an index. But for clarity and consistency,
using as_index=False is usually better for beginners, because it avoids hidden
index behavior.
-Function .agg can handle sum, count, avg, max
"""Leetcode Problem 1082: In the Table Product product_id is the primary key (column with unique values) of this table. Each row of this table indicates the name and the unit price of each product. The table Sales can have repeated rows. product_id is a foreign key (reference column) to the Product table. Each row of this table - seller_id, product_id, buyer_id, sale_date, quantity and price - contains some information about one sale. Write a solution that reports the best seller by total sales price, If there is a tie, report them all. Return the result table in any order.
CODE SECTION 25-07-3
import pandas as pd
def sales_analysis(product: pd.DataFrame, sales: pd.DataFrame) -> pd.DataFrame:
df=sales.groupby('seller_id', as_index=False)
df=df['price'].sum()
df['rank'] = df['price'].rank(method='dense', ascending=False).astype(int)
return df[df['rank']==1][['seller_id']]Leetcode Problem 1076: Table Project: (project_id, employee_id) is the primary key (combination of columns with unique values), employee_id is a foreign key (reference column) to Employee table. Each row of this table indicates that the employee with employee_id is working on the project with project_id. Table Employee: employee_id is the primary key (column with unique values) of this table. Each row of this table contains information about one employee. Write a solution to report all the projects that have the most employees. Return the result table in any order.
CODE SECTION 25-07-4
import pandas as pd
def project_employees_ii(project: pd.DataFrame, employee: pd.DataFrame)
-> pd.DataFrame:
# groups the rows by the values in the project_id column
# grouped is now a GroupBy object which you can apply aggregation functions on
grouped = project.groupby('project_id')
# returns a Series where the index is project_id and the values are the counts
counts = grouped.size()
# .reset_index() turns the Series back into a DataFrame.
# The original index (project_id) becomes a column again.
# The .size() values become a new column named 'emps'.
result = counts.reset_index(name='emps')
result['rank1'] = result['emps'].rank(method='dense', ascending=False)
.astype(int)
return result[result['rank1'] == 1][['project_id']]Categorization & Date handling in pandas
Saturday, 10.06.2023
Leetcode Problem 1435:
Given a table Sessions
with session_id as the column of unique values and duration as the time in seconds that a user has visited the application,
You want to know how long a user visits your application.
You decided to create bins of "[0-5>", "[5-10>", "[10-15>", and "15 minutes or more" and count the number of sessions on it. Write a solution to report the (bin, total). Return the result table in any order.
CODE SECTION 25-04-1
import pandas as pd
def create_bar_chart(sessions: pd.DataFrame) -> pd.DataFrame:
df = pd.DataFrame({'category': ['[0-5>','[5-10>','[10-15>','15 or more']})
sessions['bin'] = sessions['duration'].apply(classify_duration)
df = sessions.merge(df, how='right', left_on='bin', right_on='category')
df = df.groupby('category')['session_id'].count().reset_index()
df = df.rename(columns={'session_id': 'total', 'category':'bin'})
return df[['bin','total']]
def classify_duration(duration):
if duration < 300:
return '[0-5>'
elif duration < 600:
return '[5-10>'
elif duration < 900:
return '[10-15>'
else:
return '15 or more'WITH cteClassified AS (
SELECT *,
CASE
WHEN duration < 300 THEN '[0-5>'
WHEN duration < 600 THEN '[5-10>'
WHEN duration < 900 THEN '[10-15>'
ELSE '15 or more'
END AS bin
FROM Sessions
),
cteCategories AS (
SELECT '[0-5>' AS 'category' UNION ALL
SELECT '[5-10>' UNION ALL
SELECT '[10-15>' UNION ALL
SELECT '15 or more'
) //COUNT(*) in statement below would return 1 for non-existing category->NOK
SELECT g.category AS bin, COUNT(c.session_id) AS total
FROM cteClassified c
RIGHT JOIN cteCategories g
ON c.bin=g.category
GROUP BY g.category
Leetcode Problem 1294:
In the Table Countries
country_id is the primary key (column with unique values).
Each row of this table contains the ID and the name of one country.
In the table Weather
(country_id, day) is the primary key (combination of columns with unique values).
Each row of this table indicates the weather state in a country for one day.
Write a solution to find the type of weather in each country for November 2019.
The type of weather is:
Return the result table in any order.
CODE SECTION 25-04-2
def weather_type(countries: pd.DataFrame, weather: pd.DataFrame)->pd.DataFrame:
weather['day'] = pd.to_datetime(weather['day'])
df=weather
df=df[(df['day'].dt.year == 2019) & (df['day'].dt.month == 11)]
df=df.merge(countries,how='inner',on='country_id')
df = df.groupby('country_name')['weather_state'].mean().reset_index()
df = df.rename(columns={'weather_state': 'weather_type'})
df['weather_type'] = df['weather_type'].apply(classify_weather)
return df
def classify_weather(avg):
if avg <= 15:
return 'Cold'
elif avg >= 25:
return 'Hot'
else:
return 'Warm'Leetcode Problem 1853: In the Table Days day is the column with unique values. Write a solution to convert each date in Days into a string formatted as "day_name, month_name day, year". Return the result table in any order.
CODE SECTION 25-04-3
import pandas as pd
def convert_date_format(days: pd.DataFrame) -> pd.DataFrame:
days['day'] = days['day'].apply(
lambda x: f"{x.strftime('%A')}, {x.strftime('%B')} {x.day}, {x.year}"
)
# days['day'].dt.strftime('%A, %B %d, %Y') day with leading zero
return daysLeetcode Problem 1511: Table Customers: customer_id is the column with unique values for this table. This table contains information about the customers in the company - name and country. Table Product: product_id is the column with unique values for this table. This table contains information on the products in the company in the field description, and the field price contains the product cost. Table Orders: order_id is the column with unique values for this table. This table contains information on customer orders. customer_id is the id of the customer who bought "quantity" products with id "product_id". Order_date is the date in format ('YYYY-MM-DD') when the order was shipped. Write a solution to report the customer_id and customer_name of customers who have spent at least $100 in each month of June and July 2020. Return the result table in any order.
CODE SECTION 25-04-4
import pandas as pd
def customer_order_frequency(customers: pd.DataFrame,
product: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:
df = orders
df['month'] = df['order_date'].apply(get_month)
df = df[~df['month'].isna()]
df6 = df[df['month'] == 6]
df6 = df6.merge(product, on='product_id', how='inner')
df6['spent'] = df6['quantity']*df6['price']
df6 = df6.groupby('customer_id')['spent'].sum().reset_index()
df6 = df6[df6['spent'] >= 100]
df7 = df[df['month'] == 7]
df7 = df7.merge(product, on='product_id', how='inner')
df7['spent'] = df7['quantity']*df7['price']
df7 = df7.groupby('customer_id')['spent'].sum().reset_index()
df7 = df7[df7['spent'] >= 100]
c=customers
df=c[(c['customer_id'].isin(df6['customer_id']))
& (c['customer_id'].isin(df7['customer_id']))]
return df[['customer_id','name']]
def get_month(order_date):
if (order_date.year != 2020) | (order_date.month not in {6,7}):
return None
return order_date.monthParameterized queries, NULLIF, UNNEST, ARRAY_AGG
Saturday, 13.05.2023
 Codewars Problem:
Write a parameterized PostgreSQL query to fetch the accessible sections based on a given user ID.
Use $1 as a placeholder for the user ID parameter.
Input Table section_access schema:
Codewars Problem:
Write a parameterized PostgreSQL query to fetch the accessible sections based on a given user ID.
Use $1 as a placeholder for the user ID parameter.
Input Table section_access schema:
Write a prepared SQL statement named find_sections that takes a user ID as a parameter (of integer type). The query should only return sections to which the user has access. The result set should contain the columns id and section_name and should be ordered by id in ascending order.
Solution:
Checking if element is present in array is accomplished using ANY function that returns true or false. Parameter is referenced by $1.
Type conversion shorthand is :: instead of CAST(...AS...).
CODE SECTION 23-10-1
PREPARE find_sections(INT) AS
SELECT id, section_name
FROM section_access
WHERE $1::TEXT = ANY(string_to_array(user_access, ','))
ORDER BY id Codewars Problem: You work in an online retail company that uses two tables to track order processing and error handling. The first table, order_processing, keeps track of all the orders. The second table, order_errors, tracks any errors that occurred while processing these orders. Both tables have the same schema:
Now, the business wants to know the percentage of orders in the last hour that resulted in an error.
Write a SQL query that calculates the percentage of orders that resulted in an error in the last hour.
"last hour" refers to the most recent 60-minute period leading up to the current time excluding the exact boundary of 1 hour. You will need to count the number of entries in both order_processing and order_errors that have an order_time within this period and use these counts to calculate the error percentage.
The result should be a single value representing the error percentage, with the alias error_percentage, of numeric datatype and it should be rounded to two decimal places.
Notes:
You must ensure that division by zero does not occur in the query. If the count from order_processing is zero, the result should be NULL
The 1-hour interval is exclusive, meaning that records with an order_time exactly 1 hour before the current time should not be included in the counts.
Solution:
Ensuring non-0 division is accomplished using NULLIF function. PostgreSQL allows division by NULL — this is not an error, It just returns NULL. Function NULLIF(a, b) returns NULL if a = b, Otherwise, it returns a.
CODE SECTION 23-10-2
SELECT ROUND(
(
(
SELECT COUNT(*)
FROM order_errors
WHERE order_time > NOW() - INTERVAL '1 hour'
)::NUMERIC
/
NULLIF((
SELECT COUNT(*)
FROM order_processing
WHERE order_time > NOW() - INTERVAL '1 hour'
), 0)
) * 100, 2
) AS error_percentageCodewars Problem: We have a Table named books with the following schema:
Write a SQL query to achieve the following:
The output should be ordered by the number of books in each genre in descending order, and then alphabetically by genre name for genres with the same book count.
Example:
Input Table: books
| id | title | author | genres |
|---|---|---|---|
| 1 | Dune | Frank Herbert | {Sci-Fi, Adventure} |
| 2 | The Hobbit | J.R.R. Tolkien | {Fantasy, Adventure} |
| 3 | 1984 | George Orwell | {Dystopian, Sci-Fi} |
| 4 | Neuromancer | William Gibson | {Sci-Fi} |
Output Table: Books Grouped by Genre
| genre | count | books |
|---|---|---|
| Sci-Fi | 3 | {1984, Dune, Neuromancer} |
| Adventure | 2 | {Dune, The Hobbit} |
| Fantasy | 1 | {The Hobbit} |
| Dystopian | 1 | {1984} |
Solution: First part is definition of CTE named expanded. Using UNNEST function this is common pattern in PostgreSQL for flattening arrays. Function ARRAY_AGG aggregates a set of values into a single array. ARRAY_AGG(column_name) returns an array of values in the order they appear in specified column, and sorting array values is done using: ARRAY_AGG(title ORDER BY title).
CODE SECTION 23-10-3
WITH expanded AS (
SELECT id, title, UNNEST(genres) AS genre
FROM books
)
SELECT genre,
COUNT(*) AS count,
ARRAY_AGG(title ORDER BY title) AS books
FROM expanded
GROUP BY genre
ORDER BY count DESC, genre ASC
SUMMARY of very flexible function pairs for manipulating text and lists in PostgreSQL:
Leetcode Problem 1484:
Write a solution to find for each date the number of different products sold and their names.
The sold products names for each date should be sorted lexicographically.
Return the result table ordered by sell_date.
Input Table: Activities
| Column Name | Type |
|---|---|
| sell_date | date |
| product | varchar |
There is no primary key (column with unique values). Input table may contain duplicates. Each row of this table contains the product name and the date it was sold in a market.
CODE SECTION 23-10-4
WITH Uniques AS(
SELECT DISTINCT sell_date, product
FROM Activities
ORDER BY sell_date
)
SELECT sell_date,
COUNT(*) AS num_sold,
array_to_string(ARRAY_AGG(product ORDER BY product),',') AS products
FROM Uniques
GROUP BY sell_date Running total, PARTITION BY, ROW_NUMBER()
Saturday, 15.04.2023
Leetcode Problem 1204:
There is a queue of people waiting to board a bus. However, the bus has a weight limit of 1000 kilograms, so there may be some people who cannot board.
Write a solution to find the person_name of the last person that can fit on the bus without exceeding the weight limit.
The test cases are generated such that the first person does not exceed the weight limit. Note that only one person can board the bus at any given turn.
| Column Name | Type |
|---|---|
| person_id | int |
| person_name | varchar |
| weight | int |
| turn | int |
In the table Queue person_id column contains unique values.
This table has the information about all people waiting for a bus.
The person_id and turn columns will contain all numbers from 1 to n, where n is the number of rows in the table.
turn determines the order of which the people will board the bus, where turn=1 denotes the first person to board and turn=n denotes the last person to board.
weight is the weight of the person in kilograms.
Key Insight:
Aggregate Window function SUM is used to calculate running total.
CODE SECTION 23-04-1
WITH cteRunningWeight AS(
SELECT *,
SUM(weight) OVER (ORDER BY turn) AS total_weight
FROM Queue
),
cteFits AS(
SELECT * FROM cteRunningWeight
WHERE total_weight <=1000
)
SELECT person_name
FROM cteFits
ORDER BY total_weight DESC
FETCH FIRST 1 ROWS ONLY Leetcode Problem 1393: Write a solution to report the Capital gain/loss for each stock. The Capital gain/loss of a stock is the total gain or loss after buying and selling the stock one or many times. Return the result table in any order.
| Column Name | Type |
|---|---|
| stock_name | varchar |
| operation | enum |
| operation_day | int |
| price | int |
In the Table Stocks (stock_name, operation_day) is the primary key (combination of columns with unique values) for this table.
The operation column is an ENUM (category) of type ('Sell', 'Buy')
Each row of this table indicates that the stock which has stock_name had an operation on the day operation_day with the price.
It is guaranteed that each 'Sell' operation for a stock has a corresponding 'Buy' operation in a previous day. It is also guaranteed that each 'Buy' operation for a stock has a corresponding 'Sell' operation in an upcoming day.
Key Insight:
This can be solved using Window function + DISTINCT or GROUP BY + aggregate function.
Window functions compute aggregates across a partition but don’t reduce rows and GROUP BY collapses rows into groups.
GROUP BY and Window functions comparison:
✅
The window function version does more work — it computes the aggregate for every row, then you have to remove duplicates.
✅
The GROUP BY version is more efficient for pure aggregation because it only returns the grouped rows.
✅
The window function version is useful when you want to keep row-level detail and have aggregate info alongside (e.g., running totals, ranking).
✅
If you only want one row per group, the window + DISTINCT trick works but is usually less efficient and less idiomatic.
✅
Window functions can do things GROUP BY cannot, like running totals, ranks, and cumulative aggregates while preserving all rows.
✅
GROUP BY always reduces rows — you lose detail.
CODE SECTION 23-04-2
WITH cteOrdered AS(
SELECT *
FROM Stocks
ORDER BY operation_day
),
cteResult AS(
SELECT *,
CASE WHEN operation = 'Buy' THEN -price
ELSE price
END AS Result
FROM cteOrdered
) SELECT stock_name,
SUM(Result) AS capital_gain_loss
FROM cteResult
GROUP BY stock_nameSELECT DISTINCT stock_name,
SUM(Result) OVER(PARTITION BY stock_name ) AS capital_gain_loss
FROM cteResultLeetcode Problem 3564: Write a solution to find the most popular product category for each season. The seasons are defined as: Winter: December, January, February Spring: March, April, May Summer: June, July, August Fall: September, October, November. The popularity of a category is determined by the total quantity sold in that season. If there is a tie, select the category with the highest total revenue (quantity × price). Return the result table ordered by season in ascending order. The result format is in the following example.
| Column Name | Type |
|---|---|
| sale_id | int |
| product_id | int |
| sale_date | date |
| quantity | int |
| price | decimal |
| Column Name | Type |
|---|---|
| product_id | int |
| product_name | varchar |
| category | varchar |
In the table sales sale_id is the unique identifier. Each row contains information about a product sale including the product_id, date of sale, quantity sold, and price per unit. In the table products product_id is the unique identifier. Each row contains information about a product including its name and category.
CODE SECTION 23-04-3
WITH cteSeasons AS(
SELECT s.*, p.category, s.quantity*s.price AS revenue,
CASE
WHEN EXTRACT(MONTH FROM sale_date) IN (12,1,2) THEN 'Winter'
WHEN EXTRACT(MONTH FROM sale_date) IN (3,4,5) THEN 'Spring'
WHEN EXTRACT(MONTH FROM sale_date) IN (6,7,8) THEN 'Summer'
ELSE 'Fall'
END AS season
FROM sales s
JOIN products p
ON s.product_id = p.product_id
),
cteOrdered AS(
SELECT season, category, SUM(quantity) AS total_quantity,
SUM(revenue) AS total_revenue,
ROW_NUMBER() OVER(
PARTITION BY season
ORDER BY SUM(quantity) DESC, SUM(revenue) DESC) AS rownum
FROM cteSeasons
GROUP BY season, category
ORDER BY season
)
SELECT season, category, total_quantity, total_revenue
FROM cteOrdered
WHERE rownum = 1Consecutive groups and shifting logic
Saturday, 18.03.2023
Leetcode Problem 601:
Write a solution to display the records with three or more rows with consecutive id's, and the number of people is greater than or equal to 100 for each.
Return the result table ordered by visit_date in ascending order.
| Column Name | Type |
|---|---|
| id | int |
| visit_date | date |
| people | int |
In the Stadium table visit_date is the column with unique values.
Each row of this table contains the visit date and visit id to the stadium and people with the number of people during the visit.
As the id increases, the date increases as well.
Key Insights:
Applied DENSE_RANK() to assign increasing ranks by id.
Shifted the grouping by computing id - rank , which
gives the same value for rows with consecutive id values and enables grouping those together
CODE SECTION 24-07-1
WITH cteMoreThan100 AS(
SELECT *,
DENSE_RANK() OVER(ORDER BY id) AS rank
FROM Stadium
WHERE people >= 100
ORDER BY id
),
cteGroupShift AS (
SELECT *,
id - rank AS id_shift
FROM cteMoreThan100
),
cteMoreThan3 AS(
SELECT id_shift, COUNT(*) AS cnt
FROM cteGroupShift
GROUP BY id_shift
HAVING COUNT(*) >=3
)
SELECT id, visit_date, people
FROM cteGroupShift
WHERE id_shift IN (
SELECT id_shift FROM cteMoreThan3
)
ORDER BY visit_dateLeetcode Problem 1454: Write a solution to find the id and the name of active users. Active users are those who logged in to their accounts for five or more consecutive days. Return the result table ordered by id.
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| Column Name | Type |
|---|---|
| id | int |
| login_date | date |
In the Accounts table, id is the primary key (column with unique values). This table contains the account id and the user name of each account. Logins table may contain duplicate rows. This table contains the account id of the user who logged in and the login date. A user may log in multiple times in the day.
CODE SECTION 24-07-2
WITH cteRanks AS (
SELECT DISTINCT id, login_date,
DENSE_RANK() OVER (PARTITION BY id ORDER BY login_date) AS rn
FROM Logins
),
cteGroups AS (
SELECT id, DATE(login_date - (INTERVAL '1 day') * rn) AS grp, rn
FROM cteRanks
ORDER BY id, rn
),
cteCounts AS(
SELECT id, grp, COUNT(*) AS cnt
FROM cteGroups
GROUP BY id, grp
)
SELECT DISTINCT a.id, a.name
FROM cteCounts c
JOIN Accounts a
ON a.id=c.id
WHERE c.cnt>= 5
ORDER BY a.id Window functions, multi CTEs, DISTINCT ON, SUM(1)
Saturday, 18.02.2023
Codewars Problem:
You need to find the total number of interview failures grouped by the failure_reason in the interview_failures table without using the COUNT() function or relying on any auto-incrementing id column.
We have a PostgreSQL DB Table interview_failures that contains information about various unfortunate reasons candidates failed their interviews:
You need to find the total number of interview failures grouped by the failure_reason in the interview_failures table without using the COUNT() function or relying on any auto-incrementing id column. The result set should contain the following columns:
Order the results by cnt in descending order. If the count is the same for multiple reasons, order them alphabetically by the reason.
Key Insight:
Extracting item with highest Rank by ordering ranks desc and applying DISTINCT ON for particular column (not
entire record). Another way is to use SUM(1) that adds the number 1 for each row in a group, and is equivalent
to counting rows — so it's functionally the same as COUNT(*).
CODE SECTION 23-08-1
WITH cteRankMax AS (
SELECT DISTINCT ON(failure_reason) failure_reason,
DENSE_RANK() OVER (PARTITION BY failure_reason
ORDER BY interview_date) AS cnt
FROM interview_failures
ORDER BY failure_reason, cnt desc
)
SELECT *
FROM cteRankMax
ORDER BY cnt DESC, failure_reasonSELECT failure_reason, SUM(1) AS cnt
FROM interview_failures
GROUP BY failure_reason
ORDER BY cnt DESC, failure_reason
Leetcode Problem 185:
A company's executives are interested in seeing who earns the most money in each of the company's departments. A high earner in a department is an employee who has a salary in the Top three unique salaries for that department.
Write a solution to find the employees who are high earners in each of the departments.
Return the result table in any order.
In the Employee table id is the primary key (column with unique values),
departmentId is a foreign key (reference column) of the ID from the Department table.
Each row of this table indicates the ID, name, and salary of an employee. It also contains the ID of their department.
In the Department table id is the primary key (column with unique values).
Each row of this table indicates the ID of a department and its name.
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
CODE SECTION 23-08-2
WITH cteRanked AS (
SELECT d.name AS Department, e.name AS Employee,
DENSE_RANK() OVER(PARTITION BY e.departmentId
ORDER BY e.salary DESC) AS rank,
e.salary AS Salary
FROM Employee e
JOIN Department d
ON e.departmentId = d.id
)
SELECT Department, Employee, Salary
FROM cteRanked
WHERE rank <= 3
Leetcode Problem 178:
Write a solution to find the rank of the scores.
In the Table Scores
id is the primary key (column with unique values).
Each row of this table contains the score of a game. Score is a floating point value with two decimal places.
The ranking should be calculated according to the following rules:
The scores should be ranked from the highest to the lowest.
If there is a tie between two scores, both should have the same ranking.
After a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no holes between ranks.
Return the result table ordered by score in descending order.
Example of Input and output tables:
| id | score |
|---|---|
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
| score | rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
CODE SECTION 23-08-3
SELECT score,
DENSE_RANK() OVER(ORDER BY score DESC) AS rank
FROM Scores
ORDER BY score DESCScalar Subquery, BETWEEN operator
Saturday, 21.01.2023
Leetcode Problem 1251:
Write a solution to find the average selling price for each product. average_price should be rounded to 2 decimal places. If a product does not have any sold units, its average selling price is assumed to be 0.
Return the result table in any order.
Input Tables: Prices and UnitsSold
| Column Name | Type |
|---|---|
| product_id | int |
| start_date | date |
| end_date | date |
| price | int |
| Column Name | Type |
|---|---|
| product_id | int |
| purchase_date | date |
| units | int |
Table Prices:
(product_id, start_date, end_date) is the primary key (combination of columns with unique values) for this table.
Each row of this table indicates the price of the product_id in the period from start_date to end_date.
For each product_id there will be no two overlapping periods. That means there will be no two intersecting periods for the same product_id.
Table UnitsSold:
This table may contain duplicate rows.
Each row of this table indicates the date, units, and product_id of each product sold.
CODE SECTION 23-09-1
SELECT p.product_id,
CASE WHEN (
SELECT COUNT(*) FROM UnitsSold u2
WHERE u2.product_id = p.product_id
) = 0 THEN 0
ELSE ROUND(
SUM(u.units*p.price)::NUMERIC
/ (
SELECT SUM(u2.units) FROM UnitsSold u2
WHERE u2.product_id = p.product_id
GROUP BY u2.product_id
), 2)
END AS average_price
FROM UnitsSold u
RIGHT JOIN Prices p
ON u.product_id = p.product_id
AND u.purchase_date BETWEEN p.start_date AND p.end_date
GROUP BY p.product_id
Leetcode Problem 1280:
Write a solution to find the number of times each student attended each exam.
Return the result table ordered by student_id and subject_name.
Input Tables: Students, Subjects and Examinations
| Column Name | Type |
|---|---|
| student_id | int |
| student_name | varchar |
In the Table Students student_id is the primary key (column with unique values) for this table. Each row of this table contains the ID and the name of one student in the school.
| Column Name | Type |
|---|---|
| subject_name | varchar |
In the Table Subjects subject_name is the primary key (column with unique values) for this table. Each row of this table contains the name of one subject in the school.
| Column Name | Type |
|---|---|
| student_id | int |
| subject_name | varchar |
In the Table Examinations there is no primary key (column with unique values), it may contain duplicates.
Each student from the Students table takes every course from the Subjects table.
Each row of this table indicates that a student with ID student_id attended the exam of subject_name.
Key Insight: Since there may be some students that did not attend some exams and output table needs
to contain all subjects for all students there is cross join applied to tables Students and Subjects.
Example: For the following tables Students and Subjects...
| student_id | student_name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 13 | John |
| 6 | Alex |
| subject_name |
|---|
| Maths |
| Physics |
| Programming |
...Cross join will produce table with 4x3=12 records:
| student_id | student_name | subject_name |
|---|---|---|
| 1 | Alice | Math |
| 1 | Alice | Physics |
| 1 | Alice | Programming |
| 2 | Bob | Math |
| 2 | Bob | Physics |
| 2 | Bob | Programming |
| 13 | John | Math |
| 13 | John | Physics |
| 13 | John | Programming |
| 6 | Alex | Math |
| 6 | Alex | Physics |
| 6 | Alex | Programming |
Cross Join realized with CTE is finally extended with 1 column using Subquery:
CODE SECTION 23-09-2
WITH CteCrossJoin AS (
SELECT s.student_id, s.student_name, b.subject_name
FROM Students s, Subjects b
ORDER BY s.student_id, b.subject_name
)
SELECT *, (
SELECT COUNT(*) FROM Examinations e
WHERE e.student_id=sb.student_id AND e.subject_name=sb.subject_name
) AS attended_exams
FROM CteCrossJoin sbSELECT 1, INDEX, WHERE and HAVING clauses
Saturday, 24.12.2022
Codewars Problem:
You are working with a database that stores information about employees in a tech firm.
Your task is to write an SQL query that retrieves the complete record for the youngest member of each team.
The database includes a table named employees with the following columns:
The company is planning an event where the youngest employee from each team will be given a chance to share their vision of future technology trends.
You should consider the person with the latest birthdate as the youngest. Let's assume for this task that the are no youngest employees who share the same birthdate.
The classical solution of using aggregate function and group by is forbidden. Can you come up with something more witty?
The result should be ordered by team in asc alphabetical order.
Key Insights:
The SELECT 1 does not return actual data — it's just a placeholder.
It’s minimal and efficient — we only care about
existence of matching rows, not values:
✅ Fast and readable
✅ Intent is clear to humans and database engine
SELECT 1 is the cleanest and most idiomatic choice in this case.
As a common pattern understood by most SQL developers, it is the most concise, performant, and conventional choice for EXISTS.
Alternative way would be using COUNT(*) statement.
✅
NOT EXISTS stops evaluating as soon as it finds a match — it doesn't need to check all rows
✅
COUNT(*) must scan all matching e2 rows to compute the total — even if one match is enough to disqualify
✅
Most SQL engines (PostgreSQL, SQL Server, MySQL, Oracle) optimize NOT EXISTS more effectively, especially when indexes exist on team and birth_date.
✅
Adding composite index would further improve performance. It will allow the database to quickly find all e2 rows in the same team with later birthdates.
When executing query, The database engine goes through the following steps:
✅
Parses the query for syntax and structure.
✅ Builds an execution plan - how to access tables (e1, e2), whether to do full table scans, index scans, nested loops, etc.
✅ Checks for indexes - Looks at which columns are used in filtering (WHERE), sorting (ORDER BY), or joining. If there's an index on those columns, and using it is cheaper, it uses the index automatically.
✅ Executes the query based on the best plan.
After performing DML operations - INSERT, DELETE, UPDATE - index is updated automatically, behind the scenes
the DB engine maintains the index in real time.
CODE SECTION 23-05-1
SELECT e1.*
FROM employees e1
WHERE NOT EXISTS (
SELECT 1
FROM employees e2
WHERE e1.team = e2.team AND e2.birth_date > e1.birth_date
)
ORDER BY e1.team ASCSELECT e1.*
FROM employees e1
WHERE (
SELECT COUNT(*)
FROM employees e2
WHERE e1.team = e2.team AND e2.birth_date > e1.birth_date
) = 0
ORDER BY e1.team ASCCREATE INDEX idx_team_birth ON employees(team, birth_date);
Codewars Problem: In this kata you should simply determine, whether a given year is a leap year or not. In case you don't know the rules, here they are:
Tested years are in range 1600 ≤ year ≤ 4000.
CODE SECTION 23-05-2
SELECT year,
CASE
WHEN year % 400 = 0 OR( year % 4 = 0 AND year % 100 <> 0 ) THEN true
ELSE false
END AS is_leap
FROM years
ORDER BY yearCodewars Problem: Imagine you are managing an e-commerce platform. It offers a diverse range of products, each tagged with various attributes to help customers filter and find items that match their preferences. These tags could represent categories, features, styles, or any other relevant attributes. You want to implement a feature that allows customers to filter products by selecting multiple tags. Specifically, when a customer selects several tags, the platform should display only those products that are associated with all the selected tags. This ensures that the search results precisely match the customer's combined tag preferences. We have a product_tags table:
The table may contain duplicate rows where the same product is associated with the same tag multiple times.
For our task, we want to find products that are tagged with both Electronics and Gadgets. The query should return product_id values in desc order for products that are associated with both of these tags.
Example:
There is Intermediate query that groups records by product_id, and combines all rows within one group into array.
| product_id | tag |
|---|---|
| 101 | Electronics |
| 101 | Gadgets |
| 102 | Home |
| 103 | Electronics |
| 103 | Accessories |
| 104 | Kitchen |
| 105 | Electronics |
| 105 | Gadgets |
| 105 | Accessories |
| 106 | Gadgets |
| 106 | Accessories |
| product_id | tags |
|---|---|
| 101 | {Electronics,Gadgets} |
| 103 | {Electronics,Accessories} |
| 104 | {Kitchen} |
| 105 | {Electronics,Gadgets,Accessories} |
| 102 | {Home} |
| 106 | {Gadgets,Accessories} |
Output after Intermediate query execution
![]()
![]() Input table
Input table
Intermediate Query for better group overview
![]()
CODE SECTION 23-05-3
SELECT product_id, ARRAY_AGG(tag) AS tags
FROM product_tags
GROUP BY product_id| product_id |
|---|
| 105 |
| 101 |
![]() Result set of the final query contains record with product_id = 105 as well, although it has 3 tags not 2.
This was previously filtered with WHERE clause that
filters the rows before grouping. So Accessories tag is completely excluded from the analysis.
Result set of the final query contains record with product_id = 105 as well, although it has 3 tags not 2.
This was previously filtered with WHERE clause that
filters the rows before grouping. So Accessories tag is completely excluded from the analysis.
WHERE clause
HAVING clause
CODE SECTION 23-05-4
SELECT product_id
FROM product_tags
WHERE tag IN ('Electronics', 'Gadgets')
GROUP BY product_id
HAVING COUNT( DISTINCT tag ) = 2
ORDER BY product_id DESCDate functions, COALESCE, FETCH
Saturday, 26.11.2022
LeetcodeProblem 1341:
Write a solution to:
Find the name of the user who has rated the greatest number of movies. In case of a tie, return the lexicographically smaller user name.
Find the movie name with the highest average rating in February 2020. In case of a tie, return the lexicographically smaller movie name.
Input Tables: Movies - movie_id is the primary key (column with unique values), title is the name of the movie. Users - user_id is the primary key (column with unique values) for this table. The column 'name' has unique values. MovieRating - (movie_id, user_id) is the primary key (column with unique values) for this table. This table contains the rating of a movie by a user in their review. created_at is the user's review date.
| Column Name | Type |
|---|---|
| movie_id | int |
| title | varchar |
| Column Name | Type |
|---|---|
| user_id | int |
| name | varchar |
| Column Name | Type |
|---|---|
| movie_id | int |
| user_id | int |
| rating | int |
| created_at | date |
The statement FETCH FIRST 1 ROWS ONLY is applicable across many RDBMSs, and has the same effect as LIMIT 1
CODE SECTION 23-07-1
WITH cteReviews AS (
SELECT mr.user_id
FROM MovieRating mr
JOIN Users u
ON mr.user_id=u.user_id
GROUP BY mr.user_id, u.name
ORDER BY COUNT(*) DESC, u.name
FETCH FIRST 1 ROWS ONLY
)
SELECT u.name AS results
FROM Users u
JOIN cteReviews r
ON u.user_id=r.user_id
UNION ALL (
SELECT m.title
FROM MovieRating mr
JOIN Movies m
ON mr.movie_id=m.movie_id
WHERE EXTRACT(YEAR FROM mr.created_at) = 2020
AND EXTRACT(MONTH FROM mr.created_at) = 2
GROUP BY m.title
ORDER BY AVG(mr.rating) DESC, m.title
FETCH FIRST 1 ROWS ONLY
)Leetcode Problem 3220: Write a solution to find the sum of amounts for odd and even transactions for each day.
| Column Name | Type |
|---|---|
| transaction_id | int |
| amount | int |
| transaction_date | date |
The Table Transactions contains transaction_id column that uniquely identifies each row, amount and transaction date. If there are no odd or even transactions for a specific date, display as 0. Return the result table ordered by transaction_date in ascending order.
CODE SECTION 23-07-2
WITH cteOdds AS(
SELECT SUM(amount) AS odd_sum, transaction_date
FROM transactions
WHERE MOD(amount,2)=1
GROUP BY transaction_date
),
cteEvens AS (
SELECT SUM(amount) AS even_sum, transaction_date
FROM transactions
WHERE MOD(amount,2)=0
GROUP BY transaction_date
),
cteDays AS (
SELECT DISTINCT transaction_date
FROM transactions
ORDER BY transaction_date
)
SELECT d.transaction_date,
COALESCE(o.odd_sum, 0) AS odd_sum, COALESCE(e.even_sum, 0) AS even_sum
FROM cteEvens e
RIGHT JOIN cteDays d
ON e.transaction_date = d.transaction_date
LEFT JOIN cteOdds o
ON d.transaction_date = o.transaction_date
ORDER BY d.transaction_date Leetcode Problem 1070: Write a solution to find all sales that occurred in the first year each product was sold. For each product_id, identify the earliest year it appears in the Sales table. Return all sales entries for that product in that year. Return a table with the following columns: product_id, first_year, quantity, and price. Return the result in any order.
| Column Name | Type |
|---|---|
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
In the table Sales (sale_id, year) is the primary key (combination of columns with unique values) of this table. product_id is a foreign key (reference column) to Product table. Each row records a sale of a product in a given year. A product may have multiple sales entries in the same year. Note that the per-unit price.
CODE SECTION 23-07-3
SELECT s1.product_id, s1.year AS first_year, s1.quantity, s1.price
FROM Sales s1
WHERE s1.year = (
SELECT MIN(year)
FROM Sales s2
WHERE s2.product_id=s1.product_id
)Count Categories and other challenges
Saturday, 29.10.2022
Leetcode Problem 1907:
Write a solution to calculate the number of bank accounts for each salary category.
The result table must contain all three categories.
If there are no accounts in a category, return 0.
Return the result table in any order.
The salary categories are:
Input Table Accounts contains 2 fields: (account_id, income) - account_id is the primary key (column with unique values).
Each row contains information about the monthly income for one bank account.
Key Insights:
1) First CTE is used to extend input table with Category field
2) To ensure all categories present in the result set, even those where there are no bank acconts,
final SELECT is joined with CTE that contains all categories.
3) UNNEST function is PostgreSQL -specific, for MySQL and SQL Server it should be used UNION ALL.
4) To get 0 instead of NULL value for 'empty' category it is used COALESCE function
CODE SECTION 23-06-1
WITH cteCategorized AS (
SELECT *,
CASE
WHEN income < 20000 THEN 'Low Salary'
WHEN income > 50000 THEN 'High Salary'
ELSE 'Average Salary'
END AS category
FROM Accounts
),
cteAllCategories AS (
SELECT UNNEST(ARRAY['Low Salary', 'Average Salary', 'High Salary'])
AS category
),
cteCount AS (
SELECT category, COUNT(*) AS accounts_count
FROM cteCategorized
GROUP BY category
)
SELECT a.category,
COALESCE(c.accounts_count,0) AS accounts_count
FROM cteCount c
RIGHT JOIN cteAllCategories a
ON c.category=a.categoryLeetcode Problem 1934: Write a solution to find the confirmation rate of each user. The confirmation rate of a user is the number of 'confirmed' messages divided by the total number of requested confirmation messages. The confirmation rate of a user that did not request any confirmation messages is 0. Round the confirmation rate to two decimal places. Return the result table in any order.
| Column Name | Type |
|---|---|
| user_id | int |
| time_stamp | datetime |
The table Signups contains user_id column of unique values. Each row contains information about the signup time for the user with ID user_id. All users need to be present in the result set
| Column Name | Type |
|---|---|
| unit_id | int |
| time_stamp | datetime |
| action | ENUM |
Table Confirmations (user_id, time_stamp) is the primary key (combination of columns with unique values), user_id is a foreign key (reference column) to the Signups table, action is an ENUM (category) of the type ('confirmed', 'timeout').
Each row of this table indicates that the user with ID user_id requested a confirmation message at time_stamp and that confirmation message was either confirmed ('confirmed') or expired without confirming ('timeout').
Key insight:
To ensure all users are present in the result set, final SELECT is joined with Signups table.
CODE SECTION 23-06-2
WITH cteConfirm AS(
SELECT user_id, COUNT(*) AS confirm
FROM Confirmations
WHERE action='confirmed'
GROUP BY user_id
),
cteAll AS(
SELECT user_id, COUNT(*) AS all
FROM Confirmations
GROUP BY user_id
),
cteRate AS (
SELECT a.user_id, a.all all, c.confirm confirm
FROM cteAll a
JOIN cteConfirm c
ON a.user_id=c.user_id
)
SELECT s.user_id,
COALESCE(ROUND(r.confirm::NUMERIC/r.all,2),0) AS confirmation_rate
FROM Signups s
LEFT JOIN cteRate r
ON s.user_id=r.user_id
ORDER BY confirmation_rate SQL Numeric CAST, String handling and CTE
Saturday, 10.09.2022
Codewars Problem:
Each day a plant is growing by upSpeed meters. Each night that plant's height decreases by downSpeed meters due to the lack of sun heat. Initially, plant is 0 meters tall. We plant the seed at the beginning of a day. We want to know when the height of the plant will reach a certain level.
Input Table columns: up_speed: A positive integer representing the daily growth. Constraints: 5 ≤ up_speed ≤ 100.
down_speed: A positive integer representing the nightly decline. Constraints: 2 ≤ down_speed < up_speed.
desired_height: A positive integer representing the threshold. Constraints: 4 ≤ desired_height ≤ 1000.
CODE SECTION 23-11-1
SELECT ID,
CASE WHEN up_speed >= desired_height THEN 1
ELSE
CAST(CEIL((desired_height-up_speed)::NUMERIC/(up_speed-down_speed))+1 AS INT)
END AS num_days
FROM growing_plant
Codewars Problem:
Imagine we have a table named products with columns product_id and features. In this case, features is a string containing various single-character codes that represent different attributes or features of a product. For instance, each character could stand for a feature like 'waterproof', 'rechargeable', 'wireless', etc. There are no duplicate symbols within the features column for each product - each character in the features string is unique for that product (both uppercase and lowercase are allowed, but no repetitions).
The table structure is
product_id (varchar, primary key)
features (varchar(50)).
Solution: Using a cross join: FROM products, generate_series(...) - every row in products is joined with the result of generate_series. Using SUBSTRING() function with FROM and FOR to specify position and length: SUBSTRING(string FROM start_position FOR length) extracts 1 character from the features string starting at position i.
It can also be solved using regexp_split_to_table function - it splits the features string into individual characters, returning one row per character. It's a set-returning function, so for each product_id, you get multiple rows — one per character in features.
CODE SECTION 23-11-2
SELECT product_id,
SUBSTRING(features FROM i FOR 1) AS feature
FROM products, generate_series(1, LENGTH(features)) AS i
ORDER BY product_id SELECT product_id,
regexp_split_to_table(features, '') AS feature
FROM products
ORDER BY 1
Codewars Problem:
Your task is to write an SQL query for a PostgreSQL database. The database includes a table named split_titles, which consists of titles as concatenated strings. Each string is comprised of elements separated exclusively by the '+' character. Your objective is to extract the last element from each concatenated string in the title column. If the title does not contain the '+' symbol, display NULL for the last part.
Input Table split_titles:
Requirements:
Write an SQL query to select each title from the split_titles table.
Extract and display the last element from each title after splitting it by the '+' character.
If the title does not contain the '+' symbol, display NULL as the last_part.
Order the results by the id column in descending order.
Your result set should include two columns:
Solution: Checking presence of delimiter using POSITION(...IN...) function, that returns 0 if searched substring not found. Using string_to_array function that splits the string into an array using + as the delimiter. Function array_length with parameter 1 returns length of the 1st dimension of the array
CODE SECTION 23-11-3
SELECT title,
CASE WHEN POSITION('+' IN title) > 0 THEN
(string_to_array(title, '+'))[array_length(string_to_array(title, '+'), 1)]
ELSE NULL
END AS last_part
FROM split_titles
ORDER BY id DESCCodewars Problem: We have the messages table that has the following structure:
The table contains textual messages. Your task is to identify messages where the word "apple" appears at least twice, even if it's within a larger word like "apples" (regardless of word boundaries) The search should be case-insensitive, meaning "Apple", "APPLE", and "aPpLe" should all be treated as valid occurrences of the word "apple".
The query should return three columns:
Only messages with at least two occurrences of the word "apple" should be returned. The result should be ordered by id in descending order.
Solution:
Using Common Table Expression (CTE) that is a temporary result set that can be referenced within a SELECT, INSERT, UPDATE, or DELETE statement. It begins with the WITH keyword and works like a named subquery, but it is more readable and reused, avoids repeating expressions and lets you break down complex queries step by step.
CODE SECTION 23-11-4
WITH apple_positions AS (
SELECT id, message,
POSITION('apple' IN LOWER(message)) AS first_pos,
POSITION('apple' IN SUBSTRING(LOWER(message) FROM POSITION('apple'
IN LOWER(message)) + 1)) AS rel_second
FROM messages
)
SELECT id, message, first_pos + rel_second AS second_occurrence_position
FROM apple_positions
WHERE rel_second > 0
ORDER BY id DESCVarious SQL Problems
Saturday, 13.08.2022
Codewars Problem:
Given a table 'getcount' with column 'str'.
Return the count of vowels in the given string.
We will consider a, e, i, o, u as vowels for this Kata (but not y).
The input string will only consist of lower case letters and/or spaces.
Return a table with column 'str' and your result in a column named 'res'.
Solution: It can be used REGEXP_REPLACE or TRANSLATE(string, from, to) function
that takes a set of characters in the first argument (string) that should be replaced, and a set of characters that replaces the from in the string.
CODE SECTION 23-12-1
SELECT str,
LENGTH(REGEXP_REPLACE(str, '[^aeiouAEIOU]', '', 'g')) AS res
FROM getcountSELECT str,
LENGTH(str) - LENGTH(TRANSLATE(str,'aeiouAEIOU','')) AS res
FROM getcountCodewars Problem: Given a table 'trilingual_democracy' with column 'grp' (String). Switzerland has four official languages: German, French, Italian, and Romansh. When native speakers of one or more of these languages meet, they follow certain regulations to choose a language for the group. Here are the rules for groups of exactly three people:
The languages are encoded by the letters D for Deutsch, F for Français, I for Italiano, and K for Rumantsch. Your task is to write a function that takes a list of three languages and returns the language the group should use. Column 'grp' contains chars from the set 'D', 'F', 'I', 'K' create a query with: 'grp' and your result in a column named 'res' (char) 'res' is a single char from the above set ordered ascending by 'grp'. Solution: Using derived table (inline table) to find the missing language. The expression "AS l(lang)" assigns an alias: l is the table alias, lang is the column alias.
CODE SECTION 23-12-2
SELECT grp,
CASE
WHEN SUBSTRING(grp, 1, 1) = SUBSTRING(grp, 2, 1)
AND SUBSTRING(grp, 2, 1) = SUBSTRING(grp, 3, 1)
THEN SUBSTRING(grp, 1, 1) -- All same
WHEN SUBSTRING(grp, 1, 1) = SUBSTRING(grp, 2, 1)
THEN SUBSTRING(grp, 3, 1) -- First two same → minority is third
WHEN SUBSTRING(grp, 2, 1) = SUBSTRING(grp, 3, 1)
THEN SUBSTRING(grp, 1, 1) -- Last two same → minority is first
WHEN SUBSTRING(grp, 1, 1) = SUBSTRING(grp, 3, 1)
THEN SUBSTRING(grp, 2, 1) -- First and last same → minority is middle
ELSE -- All different → find the missing language
(SELECT lang -- derived table (inline table)
FROM (VALUES ('D'), ('F'), ('I'), ('K')) AS l(lang)
WHERE lang NOT IN (
SUBSTRING(grp, 1, 1),
SUBSTRING(grp, 2, 1),
SUBSTRING(grp, 3, 1)
)
LIMIT 1)
END AS res
FROM trilingual_democracy
ORDER BY grp;
Codewars Problem:
Imagine you are working for a dating app. Users of the app can "like" other users, and these interactions are stored in a database table called user_likes. The app's key feature is matching users when there is a mutual like, meaning both users have liked each other.
Input table user_likes has the following structure:
Your task is to write a query to identify mutual likes from the user_likes table. A mutual like exists when:
User A likes User B, and
User B likes User A
Additionally, you must ensure that each pair is reported only once, regardless of the order in which the users liked each other. You should always assign the smaller ID to the first column and the larger ID to the second column.
Output Columns:
Output should be sorted firstly by user1_id and secondy user2_id: both in ascending order.
Notes:
Self-likes (e.g., a user liking themselves) are not logical in the context of a dating app and do not exist in the system.
It is possible to have duplicates recorded multiple times. Your query must handle this and ensure that each match is returned only once.
Solution: Cartesian product (also known as a cross join) of the table with itself means:
Every record from the table is paired with every record from itself. If Table has 4 records, then each of those 4 records will be matched with each of the 4 records from the second alias, resulting in 16 records.
CODE SECTION 23-12-3
--enforcing order within pair to exclude duplicates
SELECT DISTINCT
LEAST(u1.liker_id, u1.liked_id) AS user1_id,
GREATEST(u1.liker_id, u1.liked_id) AS user2_id
FROM user_likes u1, user_likes u2
WHERE u1.liked_id = u2.liker_id AND u1.liker_id = u2.liked_id
ORDER BY user1_idMore examples on Cross Join (Cartesian Product) can be found here and here.
SQL Self Join
Saturday, 16.07.2022
 A Self Join is a type of a JOIN query used to compare rows within the same table. Unlike other SQL JOIN queries that join two or more tables, a self join joins a table to itself. One of the common use cases for self join is detecting / removing duplicate duplicates.
A Self Join is a type of a JOIN query used to compare rows within the same table. Unlike other SQL JOIN queries that join two or more tables, a self join joins a table to itself. One of the common use cases for self join is detecting / removing duplicate duplicates.
There are 2 fields in the Person table: id as the primary key and email.
| Column name | Type |
|---|---|
| id | int |
| person | varchar |
The following queries
There is
pandas solution
for reporting and deleting duplicates, and SQL solution follows:
CODE SECTION 24-03-1
DELETE p1 FROM Person p1 JOIN Person p2
ON p1.email = p2.email AND p2.id < p1.id;SELECT DISTINCT p1.email AS Email FROM Person p1 JOIN Person p2
ON p1.email = p2.email AND p1.id <> p2.idThere are 3 fields in the Weather table: id as the primary key, recordDate and temperature.
| Column name | Type |
|---|---|
| id | int |
| recordDate | date |
| temperature | int |
The following query find all dates' id with higher temperatures compared to its previous dates (yesterday)
CODE SECTION 24-03-2
SELECT w2.id AS id FROM Weather w1
LEFT JOIN Weather w2
ON DATEDIFF(w2.recordDate, w1.recordDate) = 1
WHERE w2.temperature > w1.temperatureOptionally for date difference can be used:
ON w2.recordDate = DATE_ADD(w1.recordDate, INTERVAL 1 DAY)
There are 4 fields in the Employee table: id as the primary key, name, salary and managerId.
| Column name | Type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| managerId | int |
The following query find the employees who earn more than their managers
CODE SECTION 24-03-3
SELECT e1.name AS Employee FROM Employee e1
JOIN Employee e2
ON e1.managerId=e2.id
WHERE e1.salary > e2.salaryLeetcode Problem 1661: The table Activities shows the user activities for a factory website. (machine_id, process_id, activity_type) is the primary key (combination of columns with unique values) of this table. machine_id is the ID of a machine. process_id is the ID of a process running on the machine with ID machine_id. activity_type is an ENUM (category) of type ('start', 'end'). timestamp is a float representing the current time in seconds. 'start' means the machine starts the process at the given timestamp and 'end' means the machine ends the process at the given timestamp. The 'start' timestamp will always be before the 'end' timestamp for every (machine_id, process_id) pair. It is guaranteed that each (machine_id, process_id) pair has a 'start' and 'end' timestamp.
| Column name | Type |
|---|---|
| machine_id | int |
| process_id | int |
| activity_type | enum |
| timestamp | float |
There is a factory website that has several machines each running the same number of processes. Write a solution to find the average time each machine takes to complete a process.
The time to complete a process is the 'end' timestamp minus the 'start' timestamp. The average time is calculated by the total time to complete every process on the machine divided by the number of processes that were run.
The resulting table should have the machine_id along with the average time as processing_time, which should be rounded to 3 decimal places.
Return the result table in any order.
Example: Activity table
| machine_id | process_id | activity_type | timestamp |
|---|---|---|---|
| 0 | 0 | start | 0.712 |
| 0 | 0 | end | 1.520 |
| 0 | 1 | start | 3.140 |
| 0 | 1 | end | 4.120 |
| 1 | 0 | start | 0.550 |
| 1 | 0 | end | 1.550 |
| 1 | 1 | start | 0.430 |
| 1 | 1 | end | 1.420 |
Output table:
| machine_id | processing_time |
|---|---|
| 0 | 0.894 |
| 1 | 0.995 |
Solution: Performing a SELF-JOIN on the Activity table. One table instance gives record with 'start' activity type and second table instance gives record with 'end' activity type. This way of pairing start and end records, resulting table has 1 record for each pair - for input table having 8 records, resulting table after pairing with SELF-JOIN has 4 records. Pairing with self-join is realized using CTE, that separates logic (pairing start/end) from aggregation and improves readability and modularity - giving the following table:
| machine_id | processing_time | start_timestamp | end_timestamp |
|---|---|---|---|
| 0 | 0 | 0.712 | 1.520 |
| 0 | 1 | 3.140 | 4.120 |
| 1 | 0 | 0.550 | 1.550 |
| 1 | 1 | 0.430 | 1.420 |
CODE SECTION 24-03-4
WITH cteSelfJoin AS (
SELECT a.machine_id, b.process_id, a.timestamp AS start_timestamp,
b.timestamp AS end_timestamp
FROM Activity a
JOIN Activity b
ON a.activity_type='start' AND b.activity_type='end'
AND a.machine_id = b.machine_id AND a.process_id = b.process_id
)
SELECT machine_id,
ROUND( AVG(end_timestamp- start_timestamp), 3 ) AS processing_time
FROM cteSelfJoin
GROUP BY machine_id SQL INNER and OUTER Join
Saturday, 18.06.2022
If specified just JOIN it means an INNER JOIN by default.
If specified LEFT JOIN or RIGHT JOIN, it means LEFT OUTER JOIN or RIGHT OUTER JOIN, they are completely equivalent — OUTER is just optional and often omitted for brevity.
While INNER JOIN returns only the matching rows from both tables, OUTER JOIN includes non-matching rows as well from the left/right table.
There is a table Employee -empId is the column with unique values for this table. Each row of this table indicates the name and the ID of an employee in addition to their salary and the id of their manager. In the table Bonus empId is a foreign key (reference column) to empId from the Employee table. Each row of this table contains the id of an employee and their respective bonus.
| Column name | Type |
|---|---|
| empid | int |
| name | varchar |
| supervisor | int |
| salary | int |
| Column name | Type |
|---|---|
| empid | int |
| bonus | int |
The following query reports the name and bonus amount of each employee with a bonus less than 1000. When value checking in WHERE clause is NULL, the row will NOT pass the condition, because NULL < 1000 is unknown (not true, not false), and SQL only selects rows where the condition evaluates to true.
CODE SECTION 24-02-1
SELECT e.name, b.bonus FROM Employee e
LEFT JOIN Bonus b ON e.empId = b.empId
WHERE b.bonus < 1000 OR b.bonus IS nullThere is a table Person -personId is the primary key (column with unique values) for this table. This table contains information about the ID of some persons and their first and last names. In the table Address -addressId is the primary key (column with unique values) for this table. Each row of this table contains information about the city and state of one person with ID = PersonId.
| Column name | Type |
|---|---|
| personId | int |
| lastName | varchar |
| lastName | varchar |
| Column name | Type |
|---|---|
| addressId | int |
| personId | int |
| city | varchar |
| state | varchar |
The following query reports the first name, last name, city, and state of each person in the Person table. If the address of a personId is not present in the Address table, report null instead.
CODE SECTION 24-02-2
SELECT p.firstName AS firstName, p.lastName AS lastName,
a.city AS city, a.state AS state
FROM Person p
LEFT JOIN Address a ON p.personId = a.personIdThere is a table Customers -id is the primary key (column with unique values) for this table. Each row of this table indicates the ID and name of a customer. In the table Orders -id is the primary key (column with unique values) for this table. customerId is a foreign key (reference columns) of the ID from the Customers table. Each row of this table indicates the ID of an order and the ID of the customer who ordered it.
| Column name | Type |
|---|---|
| id | int |
| name | varchar |
| Column name | Type |
|---|---|
| id | int |
| customerId | varchar |
The following query finds all customers who never order anything.
CODE SECTION 24-02-3
SELECT Customers.Name AS Customers
FROM Customers
LEFT JOIN Orders ON Customers.id = Orders.customerId
WHERE Orders.id IS nullSQL Basic features
Saturday, 28.05.2022
When required to be returned NULL in case of empty result set it is commony used subquery in combination with UNION ALL statement. When records are grouped using GROUP BY statement, for result filtering instead of WHERE clause it needs to be used HAVING clause.
There is a table MyNumbers - Each row of this table contains an integer and table may contain duplicates (no primary key)
| Column name | Type |
|---|---|
| num | int |
The following query reports the largest single number. If there is no single number, it reports null. A single number is a number that appeared only once in the MyNumbers table.
CODE SECTION 24-01-1
SELECT * FROM (
SELECT num FROM MyNumbers
GROUP BY num HAVING COUNT(*) = 1
ORDER BY num DESC LIMIT 1
) AS Sub
UNION ALL
SELECT NULL LIMIT 1; If used both WHERE AND HAVING first filter needs to be defined using WHERE and after grouping second filter using HAVING. There is a table Products - product_id is the primary key (column with unique values) for this table. This table contains data about the company's products. There is a table Orders - product_id is a foreign key (reference column) to the Products table, unit is the number of products ordered in order_date. This table may have duplicate rows.
| Column name | Type |
|---|---|
| product_id | int |
| product_name | varchar |
| product_category | varchar |
| Column name | Type |
|---|---|
| product_id | int |
| order_date | date |
| unit | int |
The following query reports the names of products that have at least 100 units ordered in February 2020 and their amount
CODE SECTION 24-01-2
SELECT p.product_name, SUM(o.unit) AS unit
FROM Products p
JOIN Orders o ON p.product_id=o.product_id
WHERE YEAR(o.order_date)=2020 AND MONTH(o.order_date)=2
GROUP BY o.product_id
HAVING unit >=100 Conditional statement CASE...WHEN...THEN...ELSE is used in SQL for branching. There is a table Triangle - (x, y, z) is the primary key column for this table. Each row of this table contains the lengths of three line segments.
| Column name | Type |
|---|---|
| x | int |
| y | int |
| z | int |
The following query reports for every three line segments whether they can form a triangle. There is additional column in the result set named triangle and content is generated using CASE clause and depends on x,y,z values:
CODE SECTION 24-01-3
SELECT *,
CASE
WHEN x+y>z AND x+z>y AND z+y>x THEN 'Yes'
ELSE 'No'
END AS triangle
FROM Triangle In SQL, the COUNT() function is used to count the number of rows that match a specified condition. The DISTINCT keyword is used to return only distinct (unique) values. When combined, COUNT and DISTINCT can be used to count the number of unique values in a column or a set of columns.
There is a table Activity that shows the user activities for a social media website. Column activity_type is an ENUM (category) of type ('open_session', 'end_session', 'scroll_down', 'send_message').
Note that each session belongs to exactly one user. This table may have duplicate rows.
| Column name | Type |
|---|---|
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
The following query reports the daily active user count for a period of 30 days ending 2019-07-27 inclusively. A user was active on someday if they made at least one activity on that day.
CODE SECTION 24-01-4
SELECT activity_date AS day, COUNT(DISTINCT user_id) AS active_users
FROM Activity
GROUP BY activity_date
HAVING activity_date <= "2019-07-27" AND activity_date > "2019-06-27" 
Java
Comparison
1-Length
2-Math.Abs()
a)-Math.Pow()
3-bool
1-length
2-Math.abs()
a)-Math.pow()
3-boolean
4-string
a)-Split(' '),Split('+')
b)-Trim()
c)-string.Length
d)-str[i] ==
e)-IndexOf
f)-foreach(char c in s)
g)-Char.IsLetterOrDigit
h)-Char.ToLower
i)-StringBuilder.ToString
j)-StringBuilder.Append
k)-c.ToString()
l)-StringBuilder[i]=
m)-StringBuilder[i]==
n)-new string(sb.ToString() .Reverse().ToArray())
o)-Substring(start,len)
p)-Contains
q)-Clear
r1)-str1 == str2
r2)-sb1.Equals(sb2)
r3)-sb.equals(str2)
s)-sb.Append(c, n);
t)-sb.Remove(0,1)
u)-Char.IsUpper
v1)-sb.Replace(s1,s2)
v2)-s=s.Replace(s1,s2)
4-String
a)-split(" "),split("\\+")
b)-trim()
c)-String.length()
d)-str.charAt(i)
e)-indexOf
f)-for( char c: s.toCharArray() )
g)-Character.isLetterOrDigit
h)-Character.toLowerCase
i)-StringBuilder.toString
j)-StringBuilder.append
k)-String.valueOf(c) -CharSequence
l)-StringBuilder.setCharAt
m)-StringBuilder.charAt
n)-sb.reverse().toString()
o)-substring(start,end)
First idx inclusive, Last idx exclusive
p)-contains(CharSequence)
q)-setLength(0)
r1)-str1.equals(str2)
r2)-sb1.toString().equals( sb2.toString());
r3)-sb.toString().equals(str2)
s)-for(int j=0; j<n; j++)
sb.append(c);
t)-sb.deleteCharAt(0)
u)-Character.isUpperCase
v1)-int idx=sb.indexOf
while( idx != -1) {
sb.replace(idx,idx+len,s2)
idx=sb.indexOf
v2)-s=s.replace(s1,s2)
5-x.ToString()
6-HashSet<int>
a)-Add
b)-Contains
c)-new HashSet<int>(arr)
d)-Count
e)-S.Max()
5-Integer.toString(x)
6-HashSet<Integer>
a)-add
b)-contains
c)-new HashSet<>();
for (int n : arr)
hs.add(n);
d)-size()
e)-Collections.max(S)
7-Dictionary<int, int>
a)-TryGetValue(x, out y)
b)-Add(key,value)
c)-ContainsKey(k)
d)-new()
e)-m[x[i]] += 1
f)-foreach (var item in mapFreq)
g)-item.Key, item.Value
h)-Remove
i)-GetValueOrDefault( key, defval-optional)
7-HashMap<Integer, Integer>
a)-y=map.get(x)
b)-put(key,value)
c)-containsKey(k)
d)-new HashMap<>()
e)-m.put(x[i], m.get(x[i]) + 1)
f)-for(Map.Entry<Integer, Integer> item : mapFreq.entrySet())
g)-item.getKey(), item.getValue()
h)-remove
i)-getOrDefault( k, defv)
8-Array
a)-x[1..x.length]
b)-foreach (int el in x)
c)-Array.Sort(x)
d)-Array.Copy( src, dest, len )
e)-A.Contains
8-Array
a)-Arrays.copyOfRange(x, 1, x.length);
b)-for(int el : nums)
c)-Arrays.sort(x)
d)-System.arraycopy( src,0,dest,0,len)
e)-List<String> L = Arrays.asList(A);
L.contains
9-int?
a)-Int32.MaxValue
b)-Int32.MinValue
c)-Int32.Parse
d)-int.TryParse
10-Array Convert
a) set.ToArray()
b) list.ToArray()
9-Integer
a)-Integer.MAX_VALUE
b)-Integer.MIN_VALUE
c)-Integer.parseInt
d)-try-catch ...Integer.parseInt()
10-Array Convert
a)int[] x=new int[s.size()];
int i = 0;
for (int val : s)
x[i++] = val;
b)List<String> L
L.toArray(new String[0]);
11-List<int> L = new();
a)-Add
b)-Count
c)-L[i]=x, L[i]==x
d)-IList<string> L=new List<string>(new string[n]);
e)-Reverse()
f)-List<int> L = new List<int>{1,2};
g)-L.RemoveAt(idx)
12-DateTime
a)-DateTime D = new DateTime(y, m, d)
b)-D.DayOfYear;
11-List<Integer> L=new ArrayList<>();
a)-add
b)-size()
c)-set(i,x), get(i)
d)-List<String> list=new ArrayList<>(Collections.nCopies(n, ""));
e)-Collections.reverse(L)
f)-List<Integer> L = new ArrayList<>(List.of(1, 2))
g)-L.remove(idx)
12-LocalDate
import java.time.LocalDate;
a)-LocalDate D = LocalDate.of(y, m, d);
b)-D.getDayOfYear()
13-const
14-RegEx
string s1 = Regex.Replace(s, "\\d", "");
15-Random::Next
16-(int i, int j) = (0, 0);
17-DivideByZeroException
18-Console.WriteLine
13-final
14-RegEx
String s1 = s.replaceAll("\\d", "");
15-Random::nextInt
16-int i = 0, j = 0;
17-ArithmeticException
18-System.out.println
Articles

Notes about Frontend, Backend and Database technologies, tools and languages for full stack web development.
Architecture & Design patterns
Frontend
• Binary, Hexadecimal and up to 62-base handling
• Binary search, bit count, array compare/2D copy/swap
• Perfect Square, Logarithm, Palindrome, Anagram, Add
• Maximum Depth of Binary Tree
Backend
• Reversing string words and vowels, reverse integer
• Array handling - Remove duplicates, peak index
• Basic Array, Dictionary & List handling
• HashSet, nested List and in-place Array modification
• String handling & text justifying using Round-Robin
• Two-pointer technique, Dates & circular array
• Map nested in List, sorting & ordered Map
• HTML entity parser, UTF-8 validator & RegEx
• Magic squares, X matrix, Snake & Chess problems
Data Analysis
• Pandas JOINs & column suffix, duplicates, NULLs
• DataFrame grouping & Dense Rank
• Sorting, filtering & removing duplicates
• Categorization & Date handling in pandas
Database
• Parameterized queries, NULLIF, UNNEST, ARRAY_AGG
• SQL Numeric CAST, String handling and CTE
• Scalar Subquery, BETWEEN operator
• Window functions, multi CTEs, DISTINCT ON
• Date functions, COALESCE, FETCH
• Count Categories and other challenges
• SELECT 1, INDEX, WHERE and HAVING clauses
JS Functions

isPrime
getPrimesBelow
getNprimes
getPrimeAbove
factorial
over
combinations
permutations
variations
swapInPlace
arraysAreEqual
copy2Darray
searchMatrix
diagonalPrime
transposeMatrix
matrixDeterminant
getSubMatrix
sortMap
canConstruct
reverseString
isLetter
isPalindrome
logBase
isPerfectSquare
addStrings
isPowerOfTwo
isPowerOfThree
isPowerOfFour
lastNdigits
countDigits
trailingZeroes
vowel
whitespace
validNumber
isLetter
sixBitNumber
ipv4Address
validateTime
detectCapitalUse
alphanumeric
refreshUUIDs
reverseVowels
encode
decode
parseIntEx
nextLetter
validatePassword8
validatePassword6
generatePassword
maxDepth
inorderTraversal
preorderTraversal
postorderTraversal
levelOrder
findGCD
invertBits
countSetBits
bitLength
getTwosComplement
addBinary
convertToBase2to62
convertFromBase2to62
toHexadecimal
reverseBits
searchBinary
isAnagram
convertToTitle
titleToNumber
SQL features
Returning NULL instead of empty result set
WHERE...GROUP BY...HAVING
CASE...WHEN...THEN ...ELSE...END
COUNT(DISTINCT...)
INNER/OUTER JOIN
SELF JOIN
DATEDIFF
DATE_ADD
RegEx
Derived table
CTE
SubQuery
Cartesian Product
Cross Join
Type CAST
ANY
NULLIF
ROUND
INTERVAL
LEAST
GREATEST
SUBSTRING(str,start,len)
SUBSTRING(s,FROM,FOR)
TRANSLATE
POSITION
string_to_array
generate_series
array_length
ARRAY_AGG
UNNEST
BETWEEN
Window functions
DISTINCT ON
COALESCE
FETCH
Date EXTRACT
Categorization
SUM(1)
SELECT 1
Running Total
PARTITION BY
ROW_NUMBER()
RANK()
Python
Logical AND/OR
Drop Duplicates with keep first
Sorting
INNER JOIN
LEFT JOIN
Join column suffix
NULL check
Series.apply(f)
Data Categorization
Date format
Dense Rank
Series.isin()
Series.mean()
Series.sum()
agg()
Rename column
astype(int)
to_datetime
Series.dt
lambda function
GroupBy.size()
Maria DB

Mongo DB

Mongo DB as NoSQL database is the choice when needed schema flexibility, high write throughput, or dealing with semi-structured data like JSON. For strict relational data, complex joins, and strong consistency guarantees, SQL is more appropriate.
ADVANTAGES:
DISADVANTAGES:
mongosh
Use the MongoDB Shell to test queries and interact with the data in your MongoDB database. To exit shell, run:
exit
show dbs
use myMongoDB
show collections
db.dropDatabase()
If an object tried to be accessed does not exist, Mongo DB will recreate it.
db.users.insertOne({name : "Barry"})
To show all documents in the collection, run:
db.users.find()
db.users.insertMany([{name : "Alice"},{name : "Bob"}] )
db.users.find().sort({age: 1, name : -1}).limit(2)
db.users.find().skip(1)
db.users.find({age : 50}, { name : 1, _id : 0 })
To return all fields except age, pass:
{age : 0}
db.users.find({ age : { $eq:50 }})
{ $ne:50 }
{ $gt:50 } { $gte:50 }
{ $lt:50 } { $lte:50 }
db.users.find({ name : { $in: ["Al", "Ed"] }})
{ $nin: ["Al", "Ed"] }
db.users.find({ name : { $exists: true }})
db.users.find({ name : { $exists: false }})
db.users.find({ $and: [{ age : 50},{name : "Barry"}]}) db.users.find({ $or: [{ age : { $lte: 50}},{name : "Barry"}]}) db.users.find({ $or: [{ age : { $not: { $gt: 50}}},{name : "Barry"}]})
Git

1-create new branch based on destination branch
2-make code changes and test within new branch
3-Stage changes, commit, push and publish branch
4-Create Pull request and merge changes into destination branch
1-git fetch --all
2-git reset --hard origin/branch-name
git add .
Commit
git commit -m "Msg"
Push
git push
git clone --branch BranchName --single-branch https://path/to/gitRepo LocDir
git rm --cached file.md
git add .gitignore
git commit -m "Stop tracking file.md"
git push
git init
git checkout -b MyNewBranch
git add .
git commit -m “Init commit”
git remote add origin https://path/to/gitRepo
git push -u origin MyNewBranch

1-ssh-keygen -t ed25519 -C "mail@mail.com"
2-ssh-keygen -t ed25519 -C "mail@mail.com"
3-a Get-Service ssh-agent – CHECk status
3-b Set-Service -Name ssh-agent -StartupType Automatic
3-c Start-Service ssh-agent
4-ssh-add C:\Users\User\.ssh\id_ed25519
5-Content of pub key copy to GitHub Settings – New SSH key
1-Create Repo on GitHub
2-git init
git add .
git commit -m "Init"
3-a HTTPS: git remote add origin https://github.com/username/WebDev.git 3-b SSH: git remote set-url origin git@github.com:username/WebDev.git
4-git branch -m main NewBranchName
5-git remote -v
6-git push origin NewBranchName
7-git push --set-upstream origin NewBranchName
Playwright

To start new Playwright project from scratch using VSCode, JavaScript and Edge browser:
1-Ensure node.js is installed by running:
node -v
npm -v
2-Initialize new Node.js project:
npm init -y
This will create package.json with default settings.
3. Run
a) For dev:
npm install --save-dev playwright @playwright/test
b) Remove from dev:
npm uninstall @playwright/test
npm uninstall playwright
c) For production:
npm install @playwright/test
npm install playwright
to install Playwright and its testing dependencies
4. Run
npx playwright install
to download browsers
5. Run
npm init playwright@latest
to initialize a new Playwright project
6. Run
npm cache clean --force
to clear cache
7. Run
npm install @playwright/test@latest
to update Playwright to latest version in existing project
8. Run the test
npx playwright test test.spec
9. Setup Edge-only mode -clean playwright.config.js
TypeScript

Migration from Js:
npx tsc --noEmit
to check errors in compile time
Node

To start new App in Node.js:
1. Install Node / check version:
node -v
npm -v
2. Run in project folder:
npm init -y
3. Install dependencies that will be added in package.json:
npm install mssql
4. Add new file index.js:
async function main()
Invoke main();
5. Add references using ES6:
import { db1 } from './file.js';
6. Add references using CommonJS:
const { db1 } = require('./file.js');
7. Add to package.json:
"scripts": { "newApp": "node index.js" }
8. Run new app:
npm run newApp
React
Create new React project:
Build & deploy:
const response = await fetch('/file.json'); // public dir, level index.html
Clean dev:
ASP.net
Create and run new ASP.net project:
Build & deploy:
Clean dev:
SDET
In today’s tech environment, the distinctions between developers and testers are becoming less clear, which is where Software Development Engineer in Test (SDET) comes into play. These versatile professionals combine programming skills with testing knowledge, effectively connecting development and quality assurance
